

Monitoring Kafka performance metrics
This post is Part 1 of a 3-part series about monitoring Kafka. Part 2 is about collecting operational data from Kafka, and Part 3 details how to monitor Kafka with Datadog.
What is Kafka?
Kafka is a distributed, partitioned, replicated, log service developed by LinkedIn and open sourced in 2011. Basically it is a massively scalable pub/sub message queue architected as a distributed transaction log. It was created to provide “a unified platform for handling all the real-time data feeds a large company might have”.1
There are a few key differences between Kafka and other queueing systems like RabbitMQ, ActiveMQ, or Redis’s Pub/Sub:
- As mentioned above, it is fundamentally a replicated log service.
- It does not use AMQP or any other pre-existing protocol for communication. Instead, it uses a custom binary TCP-based protocol.
- It is very fast, even in a small cluster.
- It has strong ordering semantics and durability guarantees.
Despite being pre-1.0, (current version is 0.9.0.1), it is production-ready, and powers a large number of high-profile companies including LinkedIn, Yahoo, Netflix, and Datadog.
Architecture overview
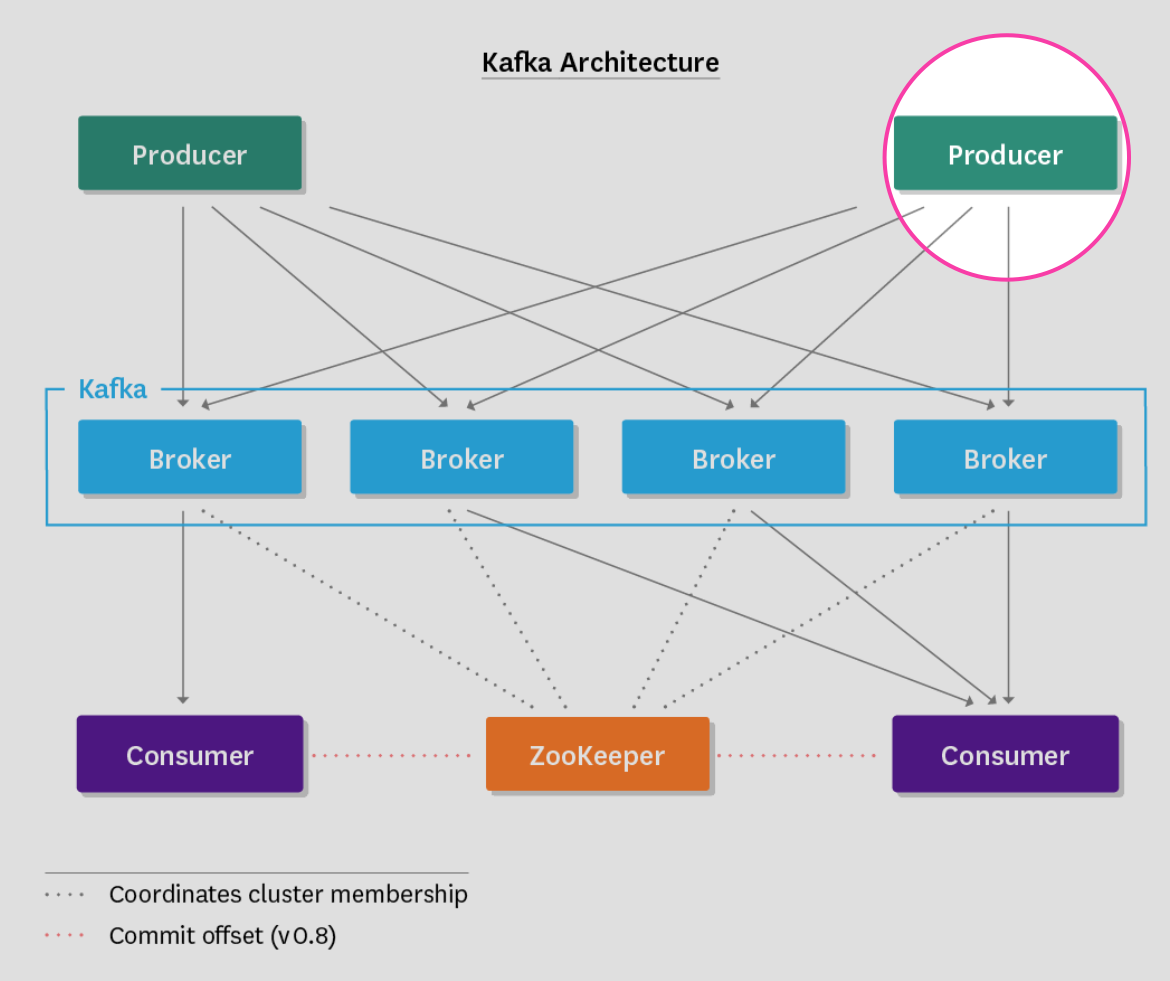
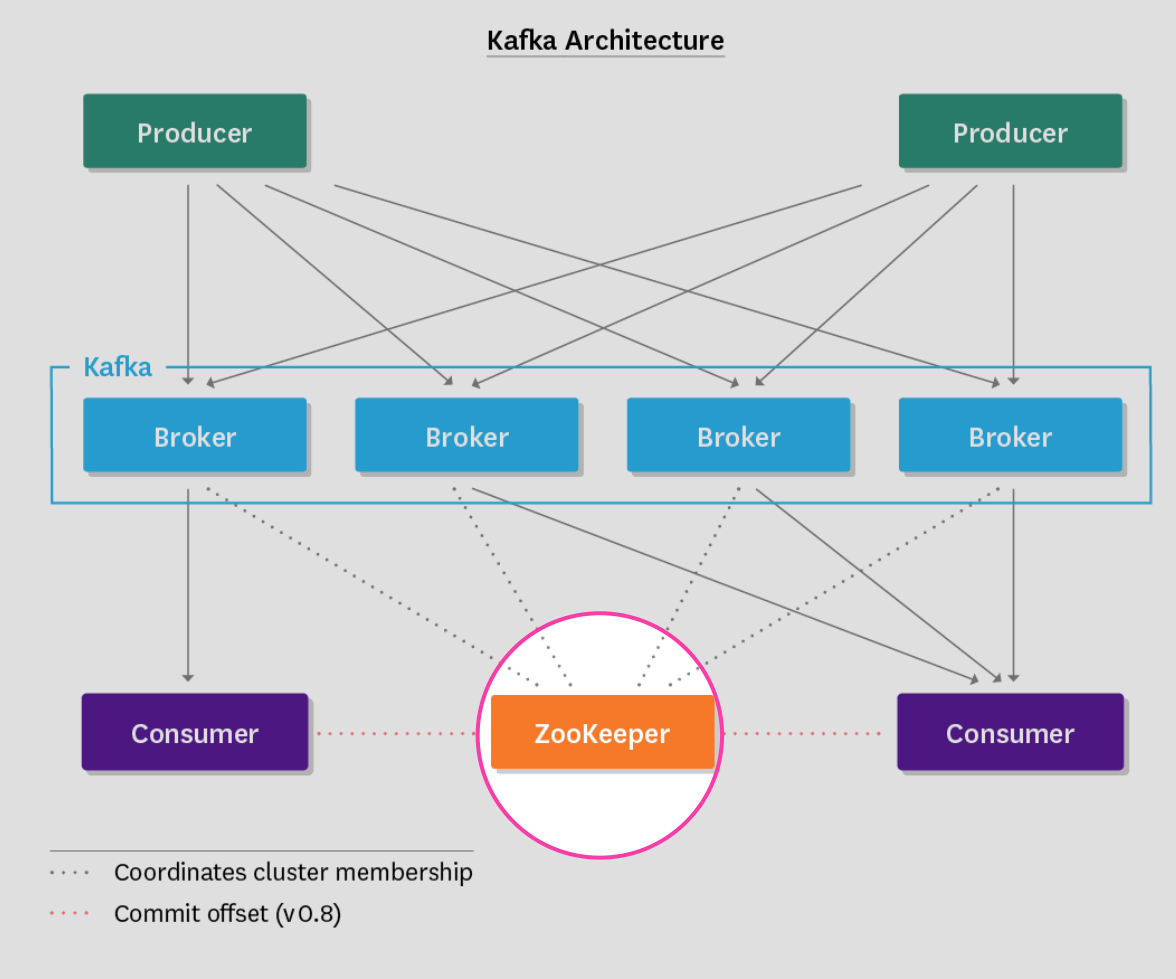
Before diving in, it is important to understand the general architecture of a Kafka deployment. Every deployment consists of the components illustrated below:
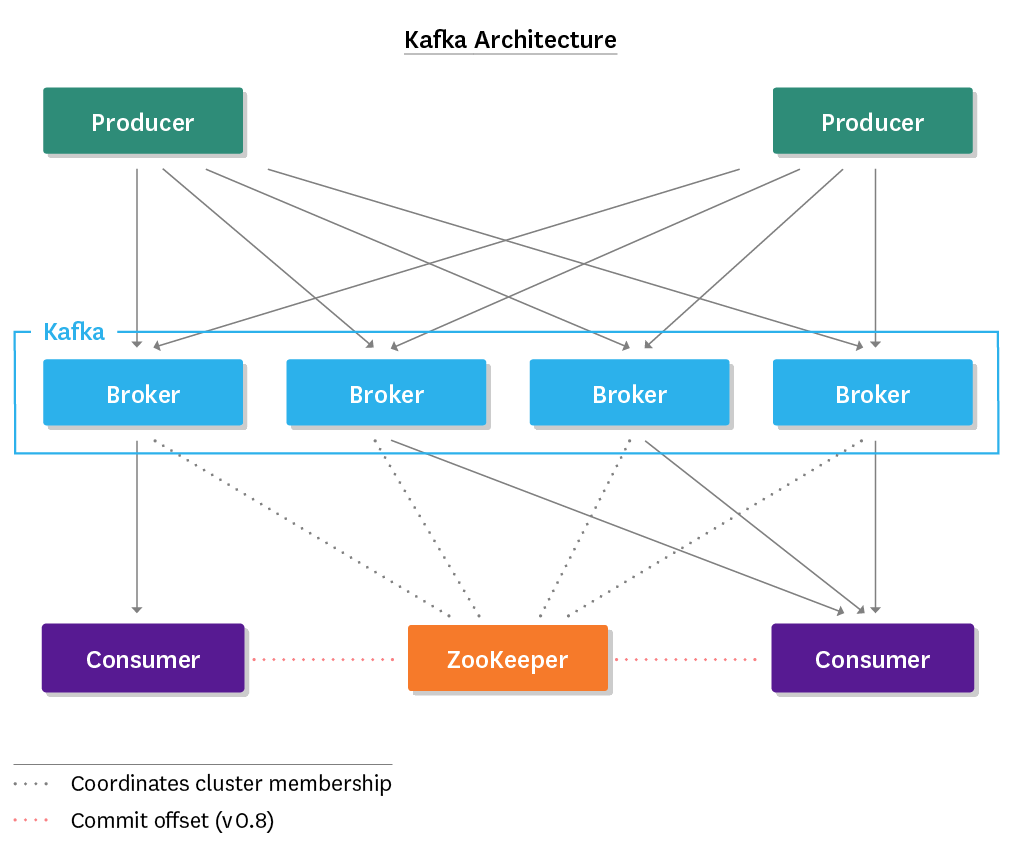
Producers publish messages to topics, and consumers (ahem) consume messages from topics. Producers and consumers operate in a push/pull fashion, with producers pushing messages to brokers (Kafka), and consumers polling brokers for new messages. Brokers are Kafka nodes and act as intermediaries, storing the published messages for consumers to pull at their own rate. This means that Kafka brokers are stateless—they do not track consumption, leaving message deletion to a configurable retention policy.
Messages consist of a payload of raw bytes, with topic and partition info encoded. Kafka groups messages by topic, and consumers subscribe to the topics they need. Messages in Kafka are ordered by timestamp and are immutable, with read as the only permitted operation.
Topics are themselves divided into partitions, and partitions are assigned to brokers. Topics thus enforce a sharding of data on the broker level. The greater the number of partitions, the more concurrent consumers a topic can support.
When setting up Kafka for the first time, you should take care to both allocate a sufficient number of partitions per topic, and fairly divide the partitions amongst your brokers. Doing so when first deploying Kafka can minimize growing pains down the road. For more information on choosing an appropriate number of topics and partitions, read this excellent article by Jun Rao of Confluent.
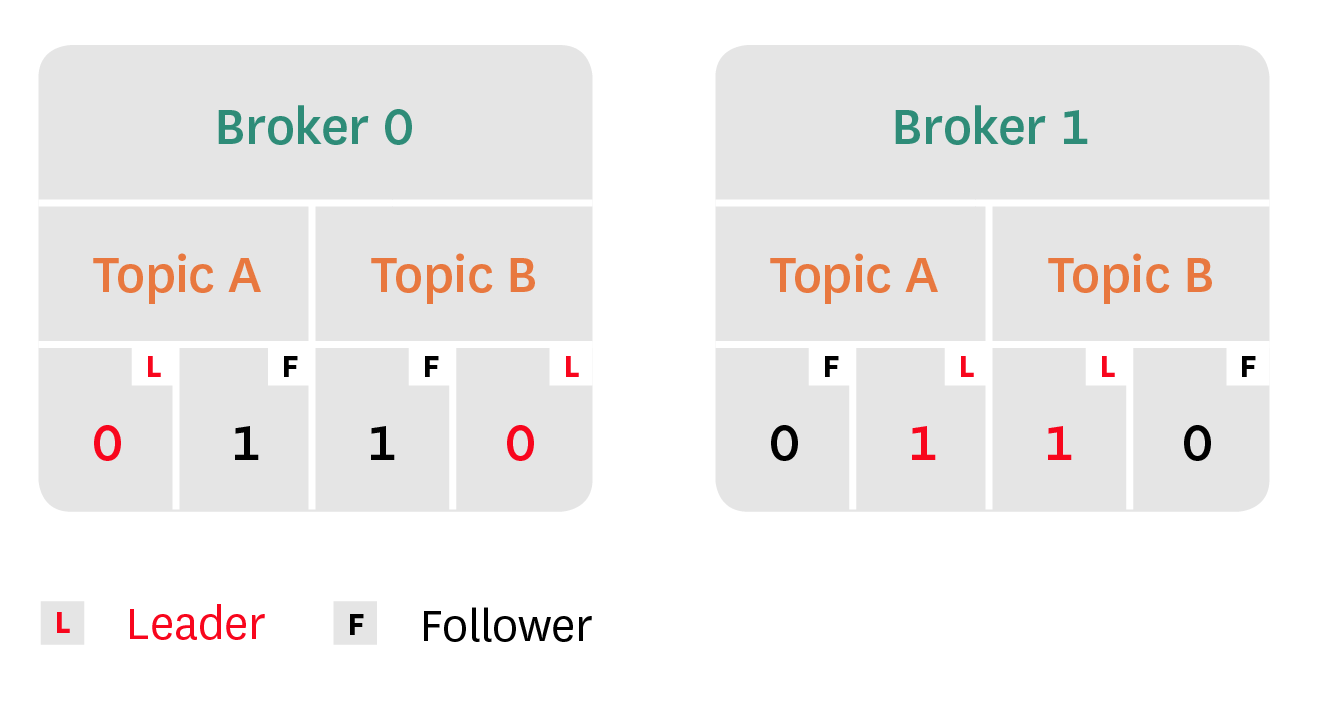
With replication enabled, each partition is replicated across multiple brokers, with the number of brokers determined by the configured replication factor. Though numerous replicas may exist, Kafka will only initiate the write on the leader of a partition, elected randomly from the pool of in-sync replicas. Additionally, consumers will only read from a partition leader. Thus, follower replicas serve as a fallback (so long as they remain in-sync) to maintain high availability in the event of broker failure.
Last but not least, no Kafka deployment is complete without ZooKeeper. ZooKeeper is the glue that holds it all together, and is responsible for:
- electing a controller (Kafka broker that manages partition leaders)
- recording cluster membership
- topic configuration
- quotas (0.9+)
- ACLs (0.9+)
- consumer group membership (removed in 0.9+)
Key metrics
A properly functioning Kafka cluster can handle a significant amount of data. With message passing platforms forming the backbone of many applications’ stacks, poor performance or a degradation in broker cluster health can easily cause issues across your entire stack.
Kafka metrics can be broken down into three categories:
In addition, because Kafka relies on ZooKeeper to maintain state, basic monitoring of ZooKeeper metrics is also necessary in a comprehensive Kafka monitoring plan. To learn more about collecting Kafka and ZooKeeper metrics, take a look at part two of this series.
This article references metric terminology introduced in our Monitoring 101 series, which provides a framework for metric collection and alerting.
Broker metrics
Kafka server metrics (aka broker metrics) provide a window into brokers, the backbone of the pipeline. Because all messages must pass through a Kafka broker in order to be consumed, monitoring and alerting on issues as they emerge in your broker cluster is critical. Broker metrics can be broken down into three classes:
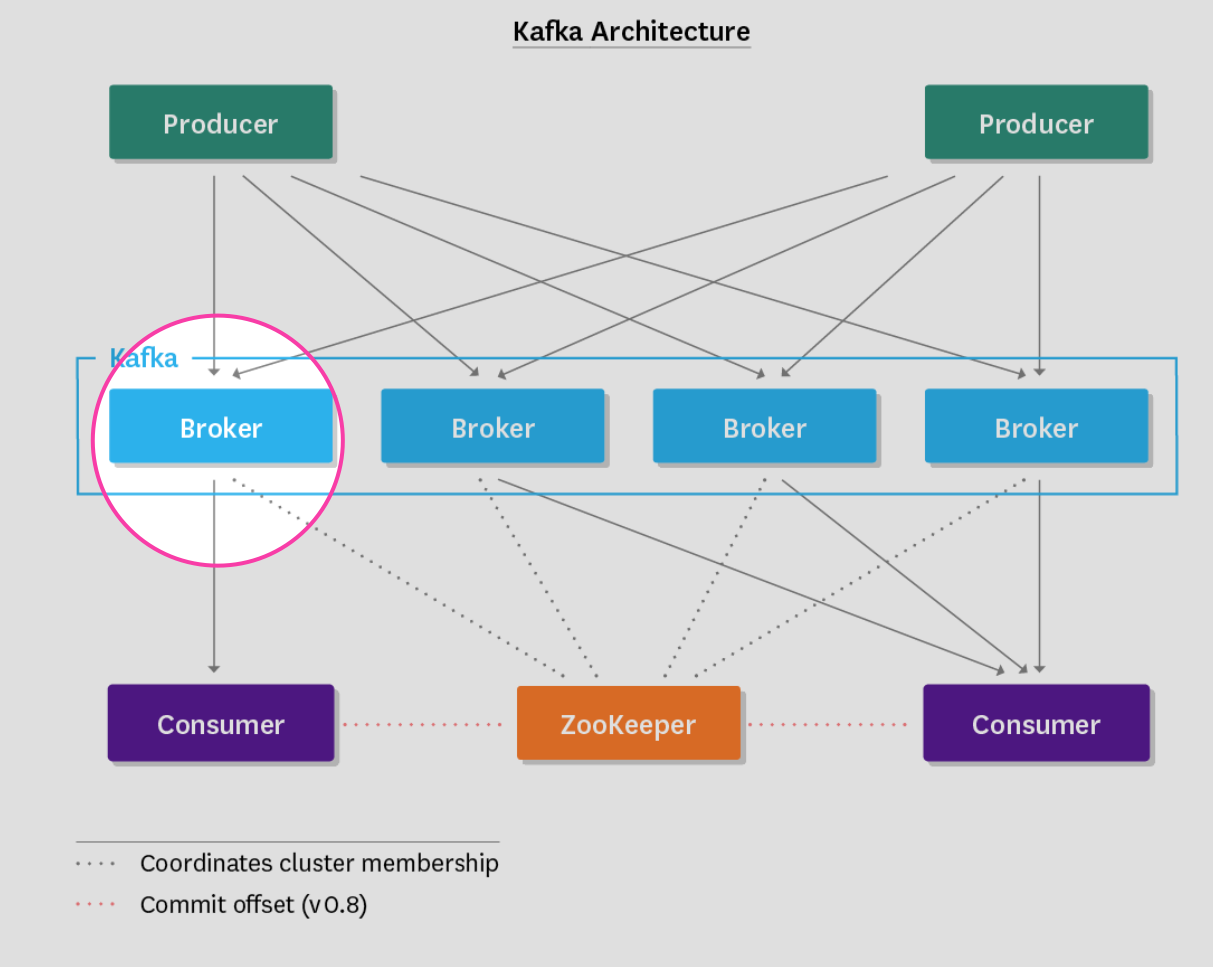
Kafka-emitted metrics
| Name | MBean Name | Description | Metric Type |
|---|---|---|---|
| UnderReplicatedPartitions | kafka.server:type=ReplicaManager, name=UnderReplicatedPartitions | Number of unreplicated partitions | Resource: Availability |
| IsrShrinksPerSec IsrExpandsPerSec | kafka.server:type=ReplicaManager, name=IsrShrinksPerSec kafka.server:type=ReplicaManager,name=IsrExpandsPerSec | Rate at which the pool of in-sync replicas (ISRs) shrinks/expands | Resource: Availability |
| ActiveControllerCount | kafka.controller:type=KafkaController, name=ActiveControllerCount | Number of active controllers in cluster | Resource: Error |
| OfflinePartitionsCount | kafka.controller:type=KafkaController, name=OfflinePartitionsCount | Number of offline partitions | Resource: Availability |
| LeaderElectionRateAndTimeMs | kafka.controller:type=ControllerStats, name=LeaderElectionRateAndTimeMs | Leader election rate and latency | Other |
| UncleanLeaderElectionsPerSec | kafka.controller:type=ControllerStats, name=UncleanLeaderElectionsPerSec | Number of "unclean" elections per second | Resource: Error |
| TotalTimeMs | kafka.network:type=RequestMetrics, name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower} | Total time (in ms) to serve the specified request (Produce/Fetch) | Work: Performance |
| PurgatorySize | kafka.server:type=ProducerRequestPurgatory,name=PurgatorySize kafka.server:type=FetchRequestPurgatory,name=PurgatorySize | Number of requests waiting in producer purgatory Number of requests waiting in fetch purgatory | Other |
| BytesInPerSec BytesOutPerSec | kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec | Aggregate incoming/outgoing byte rate | Work: Throughput |
UnderReplicatedPartitions: In a healthy cluster, the number of in sync replicas (ISRs) should be exactly equal to the total number of replicas. If partition replicas fall too far behind their leaders, the follower partition is removed from the ISR pool, and you should see a corresponding increase in IsrShrinksPerSec. Since Kafka’s high-availability guarantees cannot be met without replication, investigation is certainly warranted should this metric value exceed zero for extended time periods.
IsrShrinksPerSec/IsrExpandsPerSec: The number of in-sync replicas (ISRs) for a particular partition should remain fairly static, the only exceptions are when you are expanding your broker cluster or removing partitions. In order to maintain high availability, a healthy Kafka cluster requires a minimum number of ISRs for failover. A replica could be removed from the ISR pool for a couple of reasons: it is too far behind the leader’s offset (user-configurable by setting the replica.lag.max.messages configuration parameter), or it has not contacted the leader for some time (configurable with the replica.socket.timeout.ms parameter). No matter the reason, an increase in IsrShrinksPerSec without a corresponding increase in IsrExpandsPerSec shortly thereafter is cause for concern and requires user intervention.The Kafka documentation provides a wealth of information on the user-configurable parameters for brokers.
ActiveControllerCount: The first node to boot in a Kafka cluster automatically becomes the controller, and there can be only one. The controller in a Kafka cluster is responsible for maintaining the list of partition leaders, and coordinating leadership transitions (in the event a partition leader becomes unavailable). If it becomes necessary to replace the controller, a new controller is randomly chosen by ZooKeeper from the pool of brokers. In general, it is not possible for this value to be greater than one, but you should definitely alert on a value of zero that lasts for more than a short period (< 1s) of time.
OfflinePartitionsCount (controller only): This metric reports the number of partitions without an active leader. Because all read and write operations are only performed on partition leaders, a non-zero value for this metric should be alerted on to prevent service interruptions. Any partition without an active leader will be completely inaccessible, and both consumers and producers of that partition will be blocked until a leader becomes available.
LeaderElectionRateAndTimeMs: When a partition leader dies, an election for a new leader is triggered. A partition leader is considered “dead” if it fails to maintain its session with ZooKeeper. Unlike ZooKeeper’s Zab, Kafka does not employ a majority-consensus algorithm for leadership election. Instead, Kafka’s quorum is composed of the set of all in-sync replicas (ISRs) for a particular partition. Replicas are considered in-sync if they are caught-up to the leader, which means that any replica in the ISR can be promoted to the leader.
LeaderElectionRateAndTimeMs reports the rate of leader elections (per second) and the total time the cluster went without a leader (in milliseconds). Although not as bad as UncleanLeaderElectionsPerSec, you will want to keep an eye on this metric. As mentioned above, a leader election is triggered when contact with the current leader is lost, which could translate to an offline broker.
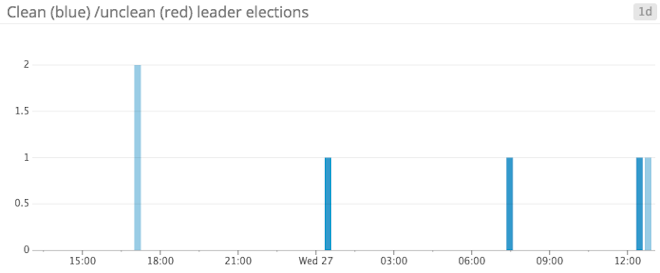
UncleanLeaderElectionsPerSec: Unclean leader elections are Very Bad™—they are caused by the inability to find a qualified partition leader among Kafka brokers. Normally, when a broker that is the leader for a partition goes offline, a new leader is elected from the set of ISRs for the partition. An unclean leader election is a special case in which no available replicas are in sync. Because each topic must have a leader, an election is held among the out-of-sync replicas and a leader is chosen—meaning any messages that were not synced prior to the loss of the former leader are lost forever. Essentially, unclean leader elections sacrifice consistency for availability. You definitely want to alert on this metric, as it signals data loss.
TotalTimeMs: The TotalTimeMs metric family measures the total time taken to service a request (be it a produce, fetch-consumer, or fetch-follower request):
produce: requests from producers to send data
fetch-consumer: requests from consumers to get new data
fetch-follower: requests from brokers that are the followers of a partition to get new data
The TotalTimeMs measurement itself is the sum of four metrics:
queue: time spent waiting in the request queue
local: time spent being processed by leader
remote: time spent waiting for follower response (only when
requests.required.acks=-1)response: time to send the response
Under normal conditions, this value should be fairly static, with minimal fluctuations. If you are seeing anomalous behavior, you may want to check the individual queue, local, remote and response values to pinpoint the exact request segment that is causing the slowdown.

PurgatorySize: The request purgatory serves as a temporary holding pen for produce and fetch requests waiting to be satisfied. Each type of request has its own parameters to determine if it will be added to purgatory:
fetch: Fetch requests are added to purgatory if there is not enough data to fulfill the request (
fetch.min.byteson consumers) until the time specified byfetch.wait.max.msis reached or enough data becomes availableproduce: If
request.required.acks=-1, all produce requests will end up in purgatory until the partition leader receives an acknowledgment from all followers.
Keeping an eye on the size of purgatory is useful to determine the underlying causes of latency. Increases in consumer fetch times, for example, can be easily explained if there is a corresponding increase in the number of fetch requests in purgatory.
BytesInPerSec/BytesOutPerSec: Generally, disk throughput tends to be the main bottleneck in Kafka performance. However, that’s not to say that the network is never a bottleneck. Depending on your use case, hardware, and configuration, the network can quickly become the slowest segment of a message’s trip, especially if you are sending messages across data centers. Tracking network throughput on your brokers gives you more information as to where potential bottlenecks may lie, and can inform decisions like whether or not you should enable end-to-end compression of your messages.
Host-level broker metrics
| Name | Description | Metric Type |
|---|---|---|
| Page cache reads ratio | Ratio of reads from page cache vs reads from disk | Resource: Saturation |
| Disk usage | Disk space currently consumed vs available | Resource: Utilization |
| CPU usage | CPU use | Resource: Utilization |
| Network bytes sent/received | Network traffic in/out | Resource: Utilization |
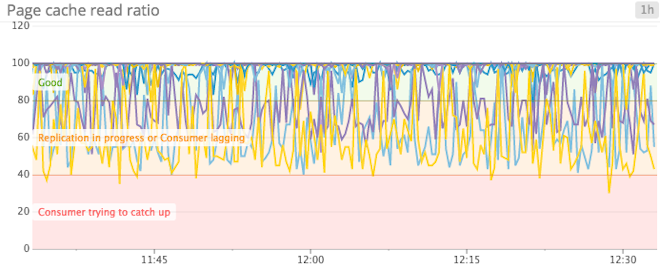
Page cache read ratio: Kafka was designed from the beginning to leverage the kernel’s page cache in order to provide a reliable (disk-backed) and performant (in-memory) message pipeline. The page cache read ratio is similar to cache-hit ratio in databases—a higher value equates to faster reads and thus better performance. If you are seeing a page cache read ratio of < 80%, you may benefit from provisioning additional brokers.
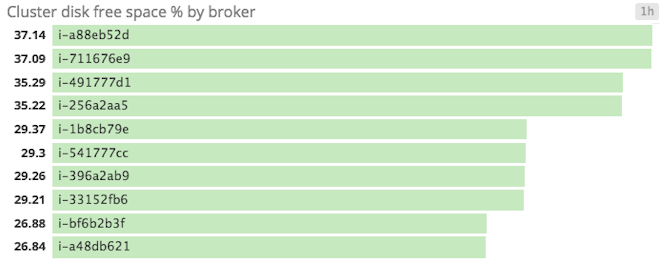
Disk usage: Because Kafka persists all data to disk, it is necessary to monitor the amount of free disk space available to Kafka. Kafka will fail should its disk become full, so keeping track of disk growth over time is recommended. Once you are familiar with the rate of data growth, you can then set alerts to inform administrators at an appropriate amount of time before disk space is all but used up.
CPU usage: Although Kafka’s primary bottleneck is usually memory, it doesn’t hurt to keep an eye on its CPU usage. Even in use cases where GZIP compression is enabled, the CPU is rarely the source of a performance problem. Therefore, if you do see spikes in CPU utilization, it is worth investigating.
Network bytes sent/received: If you are monitoring Kafka’s bytes in/out metric, you are getting Kafka’s side of the story. To get a full picture of network usage on your host, you would need to monitor host-level network throughput, especially if your Kafka brokers are hosts to other network services. High network usage could be a symptom of degraded performance—if you are seeing high network use, correlating with TCP retransmissions and dropped packet errors could help in determining if the performance issue is network-related.
JVM Garbage collection metrics
Because Kafka is written in Scala and runs in the Java Virtual Machine (JVM), it relies on Java garbage collection processes to free up memory. The more activity in your Kafka cluster, the more often the garbage collection will run.
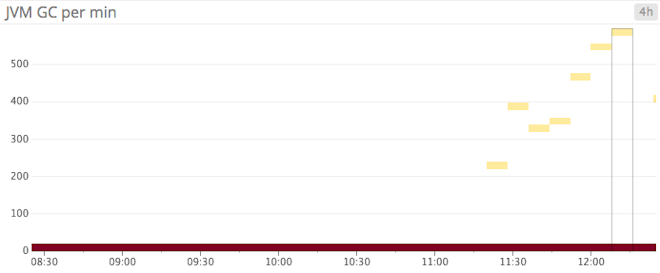
Anyone familiar with Java applications knows that garbage collection can come with a high performance cost. The most observable effect of long pauses due to garbage collection would be an increase in abandoned ZooKeeper sessions (due to sessions timing out).
The type of garbage collection depends on whether the young generation (new objects) or the old generation (long-surviving objects) is being collected. See this page for a good primer on Java garbage collection.
If you are seeing excessive pauses during garbage collection, you can consider upgrading your JDK version or garbage collector (or extend your timeout value for zookeeper.session.timeout.ms). Additionally, you can tune your Java runtime to minimize garbage collection. The engineers at LinkedIn have written about optimizing JVM garbage collection in depth. Of course, you can also check the Kafka documentation for some recommendations.
| Name | MBean Name | Description | Type |
|---|---|---|---|
| ParNew count | java.lang:type=GarbageCollector,name=ParNew | Number of young-generation collections | Other |
| ParNew time | java.lang:type=GarbageCollector,name=ParNew | Elapsed time of young-generation collections, in milliseconds | Other |
| ConcurrentMarkSweep count | java.lang:type=GarbageCollector,name=ConcurrentMarkSweep | Number of old-generation collections | Other |
| ConcurrentMarkSweep time | java.lang:type=GarbageCollector,name=ConcurrentMarkSweep | Elapsed time of old-generation collections, in milliseconds | Other |
ParNew, or young-generation, garbage collections occur relatively often. ParNew is a stop-the-world garbage collection, meaning that all application threads pause while garbage collection is carried out, so any significant increase in ParNew latency will dramatically impact Kafka’s performance.
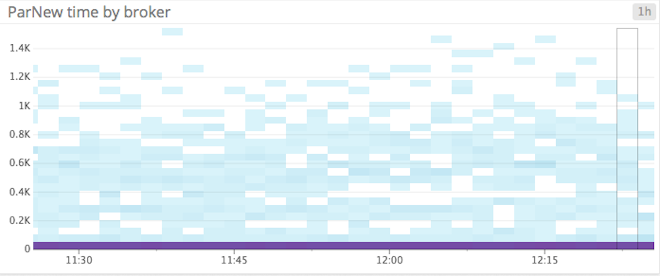
ConcurrentMarkSweep (CMS) collections free up unused memory in the old generation of the heap. CMS is a low-pause garbage collection, meaning that although it does temporarily stop application threads, it does so only intermittently. If CMS is taking a few seconds to complete, or is occurring with increased frequency, your cluster may not have enough memory to function efficiently.
Kafka producer metrics
Kafka producers are independent processes which push messages to broker topics for consumption. Should producers fail, consumers will be left without new messages. Below are some of the most useful producer metrics to monitor to ensure a steady stream of incoming data.
| Name | v0.8.2.x MBean Name | v0.9.0.x MBean Name | Description | Metric Type |
|---|---|---|---|---|
| Response rate | N/A | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of responses received per second | Work: Throughput |
| Request rate | kafka.producer:type=ProducerRequestMetrics, name=ProducerRequestRateAndTimeMs,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of requests sent per second | Work: Throughput |
| Request latency avg | kafka.producer:type=ProducerRequestMetrics, name=ProducerRequestRateAndTimeMs,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average request latency (in ms) | Work: Throughput |
| Outgoing byte rate | kafka.producer:type=ProducerTopicMetrics, name=BytesPerSec,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of outgoing/incoming bytes per second | Work: Throughput |
| IO wait time ns avg | N/A | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average length of time the I/O thread spent waiting for a socket (in ns) | Work: Throughput |
Response rate: For producers, the response rate represents the rate of responses received from brokers. Brokers respond to producers when the data has been received. Depending on your configuration, “received” could mean a couple of things:
- The message was received, but not committed (
request.required.acks == 0) - The leader has written the message to disk (
request.required.acks == 1) - The leader has received confirmation from all replicas that the data has been written to disk (
request.required.acks == -1)
This may come as a surprise to some readers, but producer data is not available for consumption until the required number of acknowledgments have been received.
If you are seeing low response rates, a number of factors could be at play. A good place to start is by checking the request.required.acks configuration directive on your brokers. Choosing the right value for request.required.acks is entirely use case dependent—it’s up to you whether you want to trade availability for consistency.
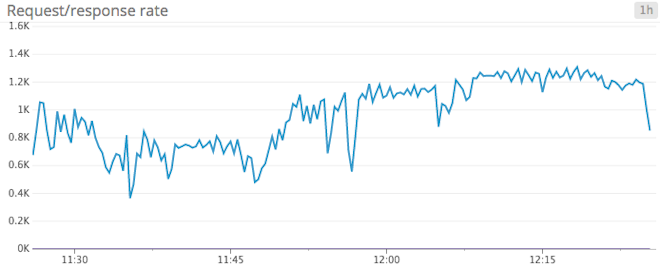
Request rate: The request rate is the rate at which producers send data to brokers. Of course, what constitutes a healthy request rate will vary drastically depending on the use case. Keeping an eye on peaks and drops is essential to ensure continuous service availability. If rate-limiting is not enabled (version 0.9+), in the event of a traffic spike brokers could slow to a crawl as they struggle to process a rapid influx of data.
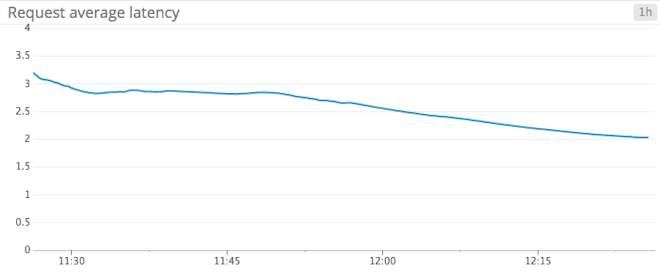
Request latency average: The average request latency is a measure of the amount of time between when KafkaProducer.send() was called until the producer receives a response from the broker. “Received” in this context can mean a number of things, as explained in the paragraph on response rate.
There are a number of ways by which you can reduce latency. The main knob to turn is the producer’s linger.ms configuration. This setting tells the producer how long it will wait before sending, in order to allow messages to accumulate in the current batch. By default, producers will send all messages immediately, as it gets an ack from the last send. However, not all use cases are alike, and in many cases, waiting a little longer for message accumulation results in higher throughput.
Since latency has a strong correlation with throughput, it is worth mentioning that modifying batch.size in your producer configuration can lead to significant gains in throughput. There is no “one size fits all” when it comes to appropriate batch size; determining an optimal batch size is largely use case dependent. A general rule of thumb is that if you have the memory, you should increase batch size. Keep in mind that the batch size you configure is an upper limit, meaning that Kafka won’t wait forever for enough data before it sends, it’ll only wait a maximum of linger.ms milliseconds. Small batches involve more network round trips, and result in reduced throughput, all other things equal.
Outgoing byte rate: As with Kafka brokers, you will want to monitor your producer network throughput. Observing traffic volume over time is essential to determine if changes to your network infrastructure are needed. Additionally, you want to be sure that your producers are sending information at a constant rate for consumers to ingest. Monitoring producer network traffic will help to inform decisions on infrastructure changes, as well as to provide a window into the production rate of producers and identify sources of excessive traffic.
IO wait time: Producers generally do one of two things: wait for data, and send data. If producers are producing more data than they can send, they end up waiting for network resources. But if producers aren’t being rate-limited or maxing-out their bandwidth, the bottleneck becomes harder to identify. Because disk access tends to be the slowest segment of any processing task, checking I/O wait times on your producers is a good place to start. Remember, I/O wait represents the percent of time spent performing I/O while the CPU was idle. If you are seeing excessive wait times, it means your producers can’t get the data they need fast enough. If you are using traditional hard drives for your storage backend, you may want to consider SSDs.
Monitoring Kafka consumer metrics

Version 0.8.2.2
In 0.8.2.2, consumer metrics are broken down into two classes: simple consumer metrics, and high-level consumer metrics.
All simple consumer metrics are also emitted by high-level consumers, but not vice versa. The key difference between the two types of consumers is the level of control afforded to developers.
Simple consumers are, well, simple in that they must be explicitly told which broker and partition to connect to. Simple consumers also have to manage their own offsets and handle partition leader elections on their own. Though they require more work to get up-and-running, simple consumers are the more flexible of the two.
High-level consumers (aka consumer groups) abstract away most of the implementation details. Details like offset positions, broker leaders, and partition availability are handled by ZooKeeper, leaving consumer groups to do what they do best: consume data. Whereas simple consumers are more powerful, high-level consumers are more flexible.
Version 0.9.0.0+
Version 0.9.0.0 of Kafka includes a number of new features, including an overhaul of the consumer API. In version 0.9+ there is a single unified class of consumer metrics exposed by the new API that combines the simple and high-level consumer metrics from version 0.8.2.2, and uses a different MBean naming scheme.
| Name | v0.8.2.x MBean Name | v0.9.0.x MBean Name | Description | Metric Type | v0.8.2.x Consumer Type |
|---|---|---|---|---|---|
| ConsumerLag MaxLag | broker offset - consumer offset kafka.consumer:type= ConsumerFetcherManager, name=MaxLag, clientId=([-.\w]+) | broker offset - consumer offset Attribute: records-lag-max, kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+) | Number of messages consumer is behind producer / Maximum number of messages consumer is behind producer | Work: Performance | Simple Consumer |
| BytesPerSec | kafka.consumer:type= ConsumerTopicMetrics, name=BytesPerSec, clientId=([-.\w]+) | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.\w]+) | Bytes consumed per second | Work: Throughput | Simple Consumer |
| MessagesPerSec | kafka.consumer:type= ConsumerTopicMetrics, name=MessagesPerSec, clientId=([-.\w]+) | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.\w]+) | Messages consumed per second | Work: Throughput | Simple Consumer |
| ZooKeeperCommitsPerSec | kafka.consumer:type= ZookeeperConsumerConnector, name=ZooKeeperCommitsPerSec, clientId=([-.\w]+) | N/A | Rate of consumer offset commits to ZooKeeper | Work: Throughput | High-level Consumer |
| MinFetchRate | kafka.consumer:type= ConsumerFetcherManager, name=MinFetchRate, clientId=([-.\w]+) | Attribute: fetch-rate, kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+) | Minimum rate a consumer fetches requests to the broker | Work: Throughput | Simple Consumer |
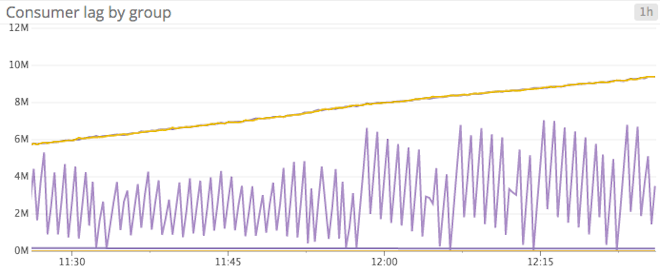
ConsumerLag/MaxLag: Everyone’s favorite Kafka metrics, ConsumerLag is the calculated difference between a consumer’s current log offset and a producer’s current log offset. MaxLag goes hand-in-hand with ConsumerLag, and is the maximum observed value of ConsumerLag. The significance of these metrics’ values depends completely upon what your consumers are doing. If you have a consumer group which backs up old messages to long-term storage, you would expect consumer lag to be significant. However, if your consumers are processing real-time data, consistently high lag values could be a sign of overloaded consumers, in which case both provisioning more consumers and splitting topics across more partitions could help increase throughput and reduce lag.
Beware: ConsumerLag is an overloaded term in Kafka—it can have the above definition, but is also used to represent the offset differences between partition leaders and their followers. If you see kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+), it is in reference to the latter, not the former.
BytesPerSec: As with producers and brokers, you will want to monitor your consumer network throughput. For example, a sudden drop in MessagesPerSec could indicate a failing consumer, but if its BytesPerSec remains constant, it’s still healthy, just consuming fewer, larger-sized messages. Observing traffic volume over time, in the context of other metrics, s important for diagnosing anomalous network usage.
MessagesPerSec: The rate of messages consumed per second may not strongly correlate with the rate of bytes consumed because messages can be of variable size. Depending on your producers and workload, in typical deployments you should expect this number to remain fairly constant. By monitoring this metric over time, you can discover trends in your data consumption and create a baseline against which you can alert. Again, the shape of this graph depends entirely on your use case, but in many cases, establishing a baseline and alerting on anomalous behavior is possible.
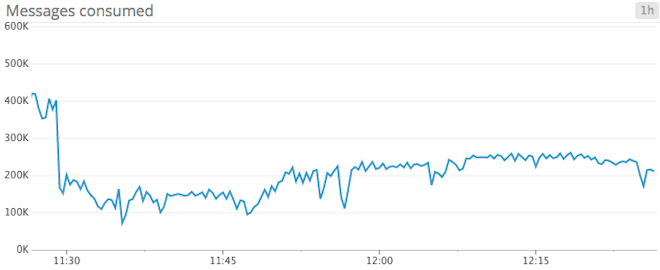
ZooKeeperCommitsPerSec v0.8x only: If you are using ZooKeeper for offset storage (the default for v0.8x, for 0.9+ you would have to explicitly specify offsets.storage=zookeeper in your configuration), you want to monitor this value. Note that even if you explicitly enable ZooKeeper offset storage in 0.9+, this metric is not exposed. When ZooKeeper is under high write load, it can become a performance bottleneck, and cause your Kafka pipeline to slow to a crawl. Tracking this metric over time can give you insight into ZooKeeper performance issues. If you consistently see a high rate of commits to ZooKeeper, you could consider either enlarging your ensemble, or changing the offset storage backend to Kafka (offsets.storage=kafka). Remember, this metric is only available for high-level consumers—simple consumers manage their own offsets.
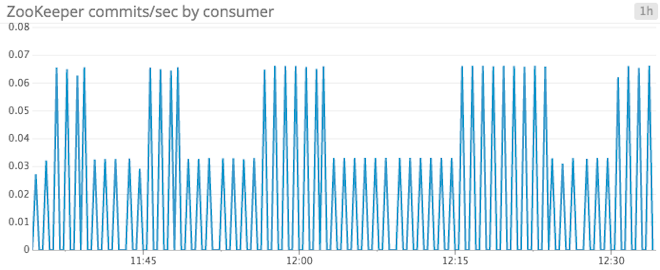
MinFetchRate: The fetch rate of a consumer can be a good indicator of overall consumer health. A minimum fetch rate approaching a value of zero could potentially signal an issue on the consumer. In a healthy consumer, the minimum fetch rate will usually be non-zero, so if you see this value dropping, it could be a sign of consumer failure.
Why ZooKeeper?
ZooKeeper plays an important role in Kafka deployments. It is responsible for: maintaining consumer offsets and topic lists, leader election, and general state information. In v0.8 of Kafka, both brokers and consumers coordinate work with ZooKeeper. In v0.9, however, ZooKeeper is used only by brokers (by default, unless otherwise configured), resulting in a substantial decrease in ZooKeeper load, especially in larger deployments.
A failure of ZooKeeper will bring your Kafka cluster to a halt as consumers will be unable to get new messages, so monitoring it is essential to maintaining a healthy Kafka cluster.
ZooKeeper metrics
ZooKeeper exposes metrics via MBeans as well as through a command line interface, using the 4-letter words. For more details on collecting ZooKeeper metrics, be sure to check out part 2 of this series.
| Name | Description | Metric Type |
|---|---|---|
zk_outstanding_requests | Number of requests queued | Resource: Saturation |
zk_avg_latency | Amount of time it takes to respond to a client request (in ms) | Work: Throughput |
zk_num_alive_connections | Number of clients connected to ZooKeeper | Resource: Availability |
zk_followers | Number of active followers | Resource: Availability |
zk_pending_syncs | Number of pending syncs from followers | Other |
zk_open_file_descriptor_count | Number of file descriptors in use | Resource: Utilization |
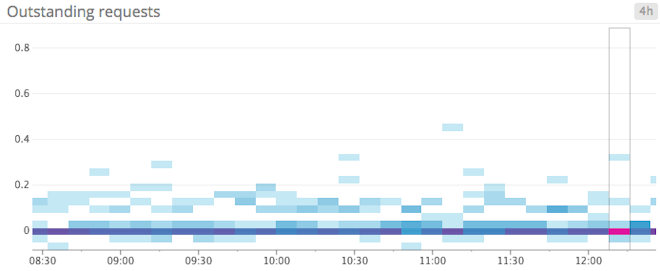
zk_outstanding_requests: Clients can end up submitting requests faster than ZooKeeper can process them. If you have a large number of clients, it’s almost a given that this will happen occasionally. To prevent using up all available memory due to queued requests, ZooKeeper will throttle clients if its queue limit is reached (zookeeper.globalOutstandingLimit). If a request waits for a while to be serviced, you will see a correlation in the reported average latency. Tracking both outstanding requests and latency can give you a clearer picture of the causes behind degraded performance.
zk_avg_latency: The average request latency is the average time it takes (in milliseconds) for ZooKeeper to respond to a request. ZooKeeper will not respond to a request until it has written the transaction to its transaction log. Along with outstanding requests and zk_pending_syncs, average request latency can offer insight into the causes of poor ZooKeeper performance when tracked over time.
zk_num_alive_connections: ZooKeeper reports the number of clients connected to it via the zk_num_alive_connections metric. This represents all connections, including connections to non-ZooKeeper nodes. In most environments, this number should remain fairly static—generally, your number of consumers, producers, brokers, and ZooKeeper nodes should remain relatively stable. You should be aware of unanticipated drops in this value; since Kafka uses ZooKeeper to coordinate work, a loss of connection to ZooKeeper could have a number of different effects, depending on the disconnected client.
zk_followers (leader only): The number of followers should equal the total size of your ZooKeeper ensemble - 1 (the leader is not included in the follower count). Changes to this value should be alerted on, as the size of your ensemble should only change due to user intervention (e.g., an administrator decommissioned or commissioned a node).
zk_pending_syncs (leader only): The transaction log is the most performance-critical part of ZooKeeper. ZooKeeper must sync transactions to disk before returning a response, thus a large number of pending syncs will result in latencies increases across the board. Performance will undoubtedly suffer after an extended period of outstanding syncs, as ZooKeeper cannot service requests until the sync has been performed. You should definitely monitor this metric and consider alerting on larger (>10) values.
zk_open_file_descriptor_count: ZooKeeper maintains state on the filesystem, with each znode corresponding to a subdirectory on disk. By default, most Linux distributions ship with a meager number of available file descriptors. After configuring your system to increase the number of available file descriptors, you should keep an eye on them to ensure they are not exhausted.
ZooKeeper system metrics
Besides metrics emitted by ZooKeeper itself, it is also worth monitoring a few host-level ZooKeeper metrics.
| Name | Description | Metric Type |
|---|---|---|
| Bytes sent/received | Number of bytes sent/received by ZooKeeper hosts | Resource: Utilization |
| Usable memory | Amount of unused memory available to ZooKeeper | Resource: Utilization |
| Swap usage | Amount of swap space used by ZooKeeper | Resource: Saturation |
| Disk latency | Time delay between request for data and return of data from disk | Resource: Saturation |
Bytes sent/received: In v0.8.x, both brokers and consumers communicate with ZooKeeper. In large-scale deployments with many consumers and partitions, this constant communication means ZooKeeper could become a bottleneck, as ZooKeeper processes requests serially. Tracking the number of bytes sent and received over time could help diagnose performance issues. Continuously high traffic volumes for your ZooKeeper ensemble could signal a need to provision more nodes for your cluster, to accommodate the higher volumes.
Usable memory: ZooKeeper should reside entirely in RAM and will suffer considerably if it must page to disk. Therefore, keeping track of the amount of usable memory is necessary to ensure ZooKeeper performs optimally. Remember, because ZooKeeper is used to store state, a degradation in ZooKeeper performance will be felt across your cluster. The machines provisioned as ZooKeeper nodes should have an ample memory buffer to handle surges in load.
Swap usage: If you run out of memory, you’ll swap, which as discussed above is not good. You’ll want to know.
Disk latency: Although ZooKeeper should reside in RAM, it still makes use of the filesystem for both periodically snapshotting its current state and for maintaining logs of all transactions. Given that ZooKeeper must write a transaction to non-volatile storage before an update takes place, this makes disk access a potential bottleneck. Spikes in disk latency will cause a degradation of service for all hosts that communicate with ZooKeeper, so besides equipping your ensemble with SSDs, you should definitely keep an eye on disk latency.
Conclusion
In this post we’ve explored many of the key metrics you should monitor to keep tabs on the health and performance of your Kafka cluster.
As a message queue, Kafka never runs in a vacuum. Eventually you will recognize additional, more specialized metrics that are particularly relevant to your own Kafka cluster and its users. For instance, you may want to correlate Kafka metrics with metrics from your consumer applications.
Read on for a comprehensive guide to collecting all of the metrics described in this article, and any other metric exposed by Kafka.
Acknowledgments
Thanks to Gwen Shapira, System Architect at Confluent, for generously sharing her Kafka expertise and monitoring strategies for this article.
Source Markdown for this post is available on GitHub. Questions, corrections, additions, etc.? Please let us know.