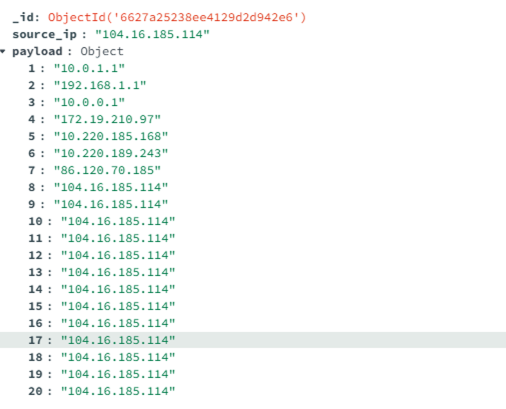
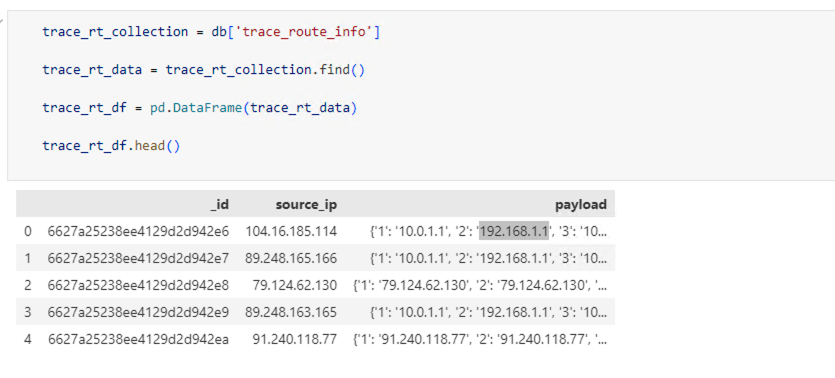
I queried, some time ago, trace route info for IP’s in a list and took the wrong decision to save it in the following form.
At first sight it’s not really an issue but if you want to retrieve it and create a dataframe it will look not as expected.
Here is the actual code to separate the payload column to column defined by keys in dictionary
import pandas as pd
# Assuming 'df' is your DataFrame and 'payload' is the column containing dictionaries
df_expanded = pd.json_normalize(trace_rt_df['payload'])
# Rename columns to match original keys (optional)
df_expanded.columns = df_expanded.columns.map(lambda x: x.split('.')[-1])
# Concatenate the expanded columns with the original DataFrame
df_final = pd.concat([trace_rt_df, df_expanded], axis=1)
# Drop the original 'payload' column (optional)
df_final.drop('payload', axis=1, inplace=True)
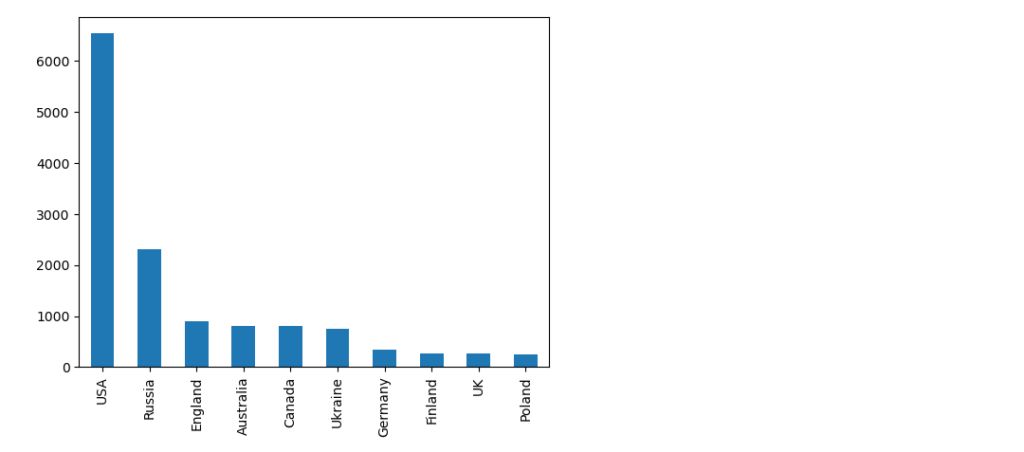
To make a long story short, if you want to plot the count for each individual column and capture the unique values of a particular column inside that dataframe, you can simply achieve it by using the following command:
We will select the first 10 countries in the series since the actual number of unique countries in the dataset is actually 118.
And the plot looks like this.
I wanted to document it because it’s an operation that I have done before, and the actual feedback from the chatbot when asked what is the solution was quite a bit more complex.
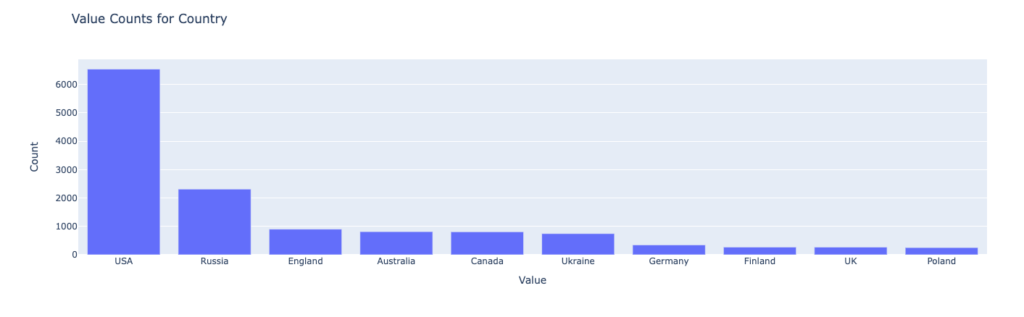
First of all it consisted of the code to filter the values and save the definition of the bar plot to a JSON file, using vega-altair library (subject for exploration at one moment in time – https://altair-viz.github.io/) and parsing the data to create the plot.
The first part worked without any issues, with the following piece of code:
import altair as alt
import pandas as pd
# Assuming df is your DataFrame (from the previous example)
# 1. Filter to column 'Country' and calculate unique value counts
value_counts = mycategory['Country'].value_counts()
# 2. Convert to DataFrame for plotting
value_counts_df = pd.DataFrame({'Value': value_counts.index, 'Count': value_counts.values})
# 3. Create bar plot
chart = alt.Chart(value_counts_df).mark_bar().encode(
x=alt.X('Value:N', axis=alt.Axis(title='Value')),
y=alt.Y('Count:Q', axis=alt.Axis(title='Count')),
tooltip=['Value', 'Count']
).properties(
title='Value Counts for Column Country'
)
# Save the chart
chart.save('value_counts_column_a_bar_chart.json')
But the second part was a little bit tricky since the chatbot didn’t have a read idea of how the structure of the file was formed, suggesting:
import plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets'][0]['data'][0]:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets'][0]['data']]
y = [d['Unique Value Count'] for d in chart_data['datasets'][0]['data']]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets'][0]['data']]
y = [d['Count'] for d in chart_data['datasets'][0]['data']]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
title='Value Counts for Column A',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
If you try to compile that it will return a KeyError:0 which is cause by the index of the chart_data[datasets][0] which is not correct.
Taking a look in the actual JSON structure you quickly find that the right key is data-85d48ef46f547bd16ab0f88b32c209fb, which bring us to the correct version:
import plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
y = [d['Unique Value Count'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
y = [d['Count'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
title='Value Counts for Country',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
Or even a more elegant one suggested by the LLM:
mport plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Find the correct data key within 'datasets'
data_key = list(chart_data['datasets'].keys())[0]
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets'][data_key][0]:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets'][data_key][:10]]
y = [d['Unique Value Count'] for d in chart_data['datasets'][data_key][:10]]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets'][data_key][:10]]
y = [d['Count'] for d in chart_data['datasets'][data_key][:10]]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
title='Value Counts for Country',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
Somewhere in the code is also a trim of the first 10 values in order to have similar outcomes. But the final plot looks like it should.
And that my friends is a small “pill” of working with Data Analysis, assisted by a LLM.
Some time ago, I tried to write some python code in order to grab each unique IP from my traffic logs and trying to trace it so that We can find similar nodes which were used for the jumps.
This is also a good exercise in order to improve the basic dataframe information and a good baseline for some explorations.
I will put here the code so that it is available for me as reference and also maybe for you if you want to take pieces of it.
I know that it is not optimised, but you can modify it or maybe use a chatbot to improve it.
import pymongo
import scapy.all as scapy
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
db = myclient["mydatabase"]
read_col = db["unique_ip"]
write_col = db["unique_ip_trace_tcp"]
lastid = 0
index_last_ip = write_col.find().sort([('_id', -1)]).limit(1)
for doc in index_last_ip:
doc['source_ip']
index_id = read_col.find({"payload":doc['source_ip']})
for elem in index_id:
lastid=elem['id']
print(lastid)
for i in range(lastid, read_col.count_documents({})):
mydoc = read_col.find({ "id": i })
for x in mydoc:
try:
for element in x['payload']:
response = {}
ans, unans = scapy.traceroute(element)
response['source_ip'] = element
payload = {}
for sdr,rcv in ans:
payload[str(sdr.ttl)]= rcv.src
response['payload'] = payload
write_col.insert_one(response)
except Exception as e:
print(e)
continue
I am putting this here more as a reference since this error appeared a couple of time when using urllib library.
For example there is the classical case of
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://en.wikipedia.org/wiki/Kevin_Bacon')
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find_all('a'):
if 'href' in link.attrs:
print(link.attrs['href'])
And if you run it for the first time in your Jupyter Kernel, it will return
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)>
The easiest way to fix it is by adding two extra lines to the code
from urllib.request import urlopen
import ssl
from bs4 import BeautifulSoup
ssl._create_default_https_context = ssl._create_unverified_context
html = urlopen('http://en.wikipedia.org/wiki/Kevin_Bacon')
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find_all('a'):
if 'href' in link.attrs:
print(link.attrs['href'])
The first one is to import the ssl library and the second one to actually create an unverified context.
The interesting fact is that once this is loaded to the kernel, it will actually work even if you comment the lines and re-execute it.
I wanted for Gemini to take a look on the code that I posted here
Here is his answer:
Absolutely! Here’s a breakdown of improvements and considerations for refining the provided web scraping code:
Enhancements:
Robust Error Handling: Incorporate try-except blocks around the scraping logic and network calls. This will prevent the script from crashing due to unexpected issues like elements not being found or the website being temporarily down.
Optimized Waits: Replace the fixed time.sleep(2) with more precise WebDriverWait conditions. For instance, wait for specific elements that indicate successful loading. This improves efficiency.
Reusable Function: Convert the alcopascrap function to accept additional parameters (like wait times) for greater flexibility in various scraping scenarios.
Data Cleaning: Within the loop, sanitize the extracted data, removing unnecessary whitespace or non-standard characters to ensure data consistency.
Comments: Add clear comments to explain the purpose of different code sections, which is crucial for understanding and maintenance.
Optimization Considerations
Scrolling Logic: Investigate if the website uses infinite scroll or lazy loading. If it does, adjust the scrolling logic to trigger loading of new content only when necessary.
Parallelism (Advanced): Consider parallelizing requests for different brands using threading or multiprocessing, especially if the scraping scope is large.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import time
def alcopascrap(brand, max_wait_time=10):
driver = webdriver.Chrome()
try:
driver.get(f"https://www.alcopa-auction.fr/ro/cautare?brand={brand}")
WebDriverWait(driver, max_wait_time).until(
EC.element_to_be_clickable((By.ID, "CybotCookiebotDialogBodyButtonAccept"))
).click()
# Optimized scrolling (Implementation depends on the site's scrolling mechanism)
list_of_cars = []
ratings = soup.find_all('div',{'data-brand':brand})
for rating in ratings:
data = {}
try:
data['title'] = rating.find('li',{'class':'mb-2 list-group-item border-0 p-0'}).get_text().strip()
data['price'] = rating['data-prices']
data['details'] = [element.get_text().strip() for element in rating.find_all('li', {'class':'list-group-item border-0 p-0'})]
data['link'] = rating.find('a', {'class':'no-decoration'}).get('href')
list_of_cars.append(data)
except NoSuchElementException:
print(f"Error processing car data in rating block: {rating}")
# ... (rest of your code)
except TimeoutException:
print(f"Timeout waiting for elements on page for brand: {brand}")
finally:
driver.quit()
alcopascrap('nissan')
Just for reference a small example of scrapping https://www.alcopa-auction.fr/ for new cars on specific brand.
It can be improved a lot but just as a reference of the code.
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
import time
# Set up a headless browser
driver = webdriver.Chrome()
# Load the website with JavaScript
def alcopascrap(brand):
driver.get(f"https://www.alcopa-auction.fr/ro/cautare?brand={brand}")
# Wait for JavaScript to execute (adjust wait time if needed)
driver.implicitly_wait(180)
WebDriverWait(driver, 1).until(
EC.element_to_be_clickable((By.ID, "CybotCookiebotDialogBodyButtonAccept"))
).click()
# Get initial scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait for loading
time.sleep(2) # Adjust wait time as needed
# Calculate new scroll height and compare with previous
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# Get the HTML source with JavaScript modifications
html_source = driver.page_source
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(html_source, 'html.parser')
#Create a list to store the data
list_of_cars = []
# Now you can use BeautifulSoup to extract the data you need
# ...
ratings = soup.find_all('div',{'data-brand':brand})
for rating in ratings:
data = {}
data['title'] = rating.find('li',{'class':'mb-2 list-group-item border-0 p-0'}).get_text()
data['price'] = rating['data-prices']
data['details'] = [ element.get_text().strip() for element in rating.find_all('li',{'class':'list-group-item border-0 p-0'})]
data['link'] = rating.find('a', {'class':'no-decoration'}).get('href')
list_of_cars.append(data)
# Print the data
for car in list_of_cars:
print(car, end='\n')
# Close browser
driver.quit()
alcopascrap('nissan')
As for the code description, here is the one from Github Copilot, you judge if it’s good or not.
This Python script uses Selenium and BeautifulSoup to scrape car data from the Alcopa Auction website. Here’s a step-by-step breakdown:
Import necessary libraries: BeautifulSoup for parsing HTML, Selenium for browser automation, and time for controlling the script’s timing.
Set up a headless browser using Selenium’s webdriver. This script uses Chrome as the browser.
Define a function alcopascrap(brand), which takes a car brand as an argument and scrapes data for that brand from the website.
The function first navigates to the Alcopa Auction website’s search page for the specified brand.
It waits for the page to load, then clicks the accept button on the cookie consent dialog.
It then enters a loop where it continually scrolls to the bottom of the page, waits for more content to load, and repeats until no more new content is loaded. This is done to ensure all the dynamic content loaded by JavaScript is captured.
After all content is loaded, it gets the page’s HTML source.
It then parses the HTML using BeautifulSoup.
It creates an empty list list_of_cars to store the car data.
It finds all div elements with a data-brand attribute matching the specified brand. For each of these elements, it extracts the car title, price, details, and link, and stores them in a dictionary. Each dictionary is then appended to list_of_cars.
It prints out the data for each car.
Finally, it closes the browser.
The function is then called with ‘nissan’ as the argument, so it scrapes data for Nissan cars.
This script is a good example of how to use Selenium and BeautifulSoup together to scrape data from a website that uses JavaScript to load content.
Currently I am reading one of the chapters from Python Data Science Handbook and saw that there are some magic commands that can be used in IPython.
One of them gives you the possibility to time the execution and it’s called %timeit. Going further it seems that there are other commands like %prun but it is not present in plain old Python, so I asked Gemini, the lovely chatbot, what were the alternatives. Here is his answer:
Unfortunately, there’s no single command in standard Python that perfectly replicates the functionality of IPython’s %prun magic command. Let me explain why and provide the closest alternatives:
What %prun Does
IPython’s %prun offers detailed profiling of a code statement. It shows you:
Number of times each function was called.
Time spent in each function (cumulative and per-call).
Provides line-by-line profiling, showing execution time for each code line within a function.
Timeit Module:
Best for measuring short code snippets’ execution time.
Not a full-fledged profiler, but useful for quick timing comparisons.
Example: Using cProfile
Python
import cProfile
def my_function(): # Code you want to profile
if __name__ == ‘__main__’: cProfile.run(‘my_function()’)
Choosing the Right Tool
For general profiling: cProfile is a good starting point.
For line-by-line analysis: Consider line_profiler.
For simple timing: timeit is sufficient.
So I tried to install line_profiler with pip, created a test py file with the example from the book
@profile
def sum_of_lists(N):
total = 0
for i in range(5):
L = [j ^ (j >> i) for j in range(N)]
total += sum(L)
return total
sum_of_lists(1000000)
It seems like in order to grab the statistics you need to use kernprof which I likely found in my anaconda installation.
I executed it with the following output
kernprof -l lineprofiler_test.py
Wrote profile results to lineprofiler_test.py.lprof
Inspect results with:
python -m line_profiler -rmt "lineprofiler_test.py.lprof"
python -m line_profiler -rmt "lineprofiler_test.py.lprof"
Timer unit: 1e-06 s
Total time: 0.906589 s
File: lineprofiler_test.py
Function: sum_of_lists at line 1
Line # Hits Time Per Hit % Time Line Contents
==============================================================
1 @profile
2 def sum_of_lists(N):
3 1 21.0 21.0 0.0 total = 0
4 6 51.0 8.5 0.0 for i in range(5):
5 5 862782.0 172556.4 95.2 L = [j ^ (j >> i) for j in range(N)]
6 5 43735.0 8747.0 4.8 total +=sum(L)
7 1 0.0 0.0 0.0 return total
0.91 seconds - lineprofiler_test.py:1 - sum_of_lists
Which is kind of cool taking into consideration that we wrote in the past a lot of scripts without optimising for performance.
Check it again and we also see that there are also two columns that are not really required: index and message which was returned by whois API. We drop those as well
And now we are finally ready to convert it and put it back to the database
# Convert DataFrame to a list of records
records = merged_df.to_records(index=False)
# Connect to MongoDB
client = MongoClient('localhost', 27017)
db = client['mydatabase']
base_merged_data = db['base_merged_data']
# Insert records into MongoDB collection
dicts = []
for record in records:
record_dict = {}
for field_name, value in zip(merged_df.columns, record):
record_dict[field_name] = value
dicts.append(record_dict)
base_merged_data.insert_many(dicts)
What I can tell you is that insert_many method is significantly faster than insert_one. At first I played with insert_one and it took 12 min to do the job, and with insert_many, that time was reduced to 3 min.