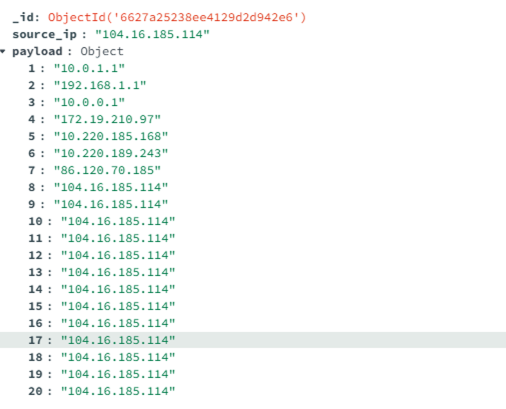
I queried, some time ago, trace route info for IP’s in a list and took the wrong decision to save it in the following form.
At first sight it’s not really an issue but if you want to retrieve it and create a dataframe it will look not as expected.
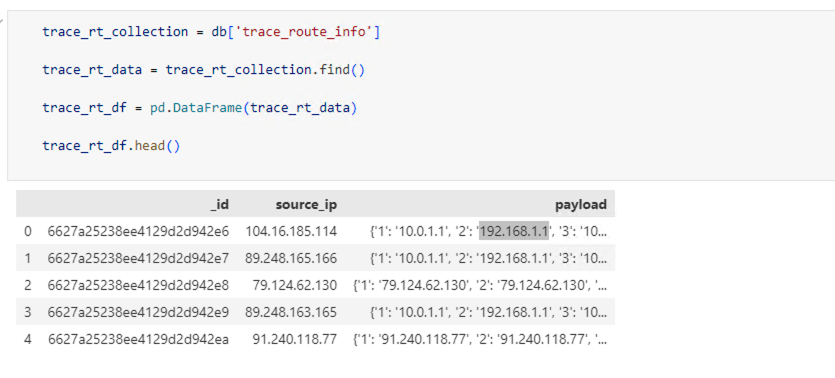
Here is the actual code to separate the payload column to column defined by keys in dictionary
import pandas as pd
# Assuming 'df' is your DataFrame and 'payload' is the column containing dictionaries
df_expanded = pd.json_normalize(trace_rt_df['payload'])
# Rename columns to match original keys (optional)
df_expanded.columns = df_expanded.columns.map(lambda x: x.split('.')[-1])
# Concatenate the expanded columns with the original DataFrame
df_final = pd.concat([trace_rt_df, df_expanded], axis=1)
# Drop the original 'payload' column (optional)
df_final.drop('payload', axis=1, inplace=True)
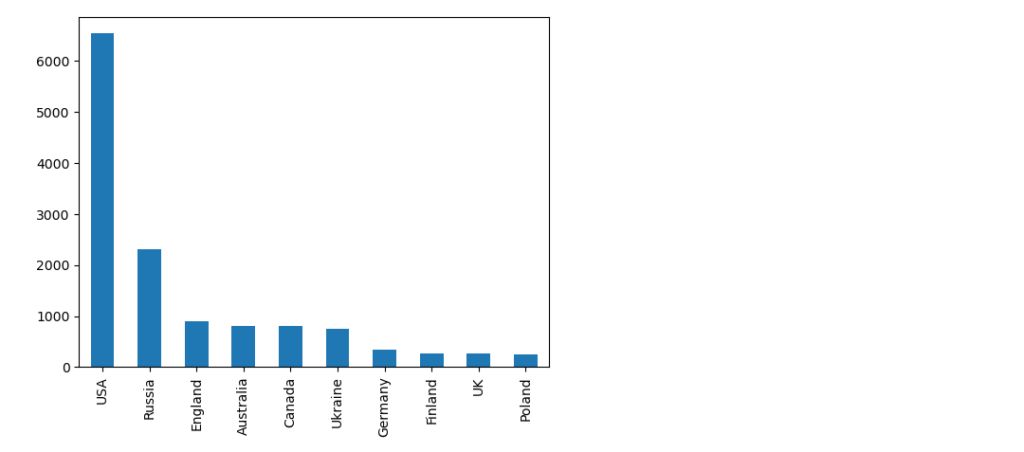
To make a long story short, if you want to plot the count for each individual column and capture the unique values of a particular column inside that dataframe, you can simply achieve it by using the following command:
We will select the first 10 countries in the series since the actual number of unique countries in the dataset is actually 118.
And the plot looks like this.
I wanted to document it because it’s an operation that I have done before, and the actual feedback from the chatbot when asked what is the solution was quite a bit more complex.
First of all it consisted of the code to filter the values and save the definition of the bar plot to a JSON file, using vega-altair library (subject for exploration at one moment in time – https://altair-viz.github.io/) and parsing the data to create the plot.
The first part worked without any issues, with the following piece of code:
import altair as alt
import pandas as pd
# Assuming df is your DataFrame (from the previous example)
# 1. Filter to column 'Country' and calculate unique value counts
value_counts = mycategory['Country'].value_counts()
# 2. Convert to DataFrame for plotting
value_counts_df = pd.DataFrame({'Value': value_counts.index, 'Count': value_counts.values})
# 3. Create bar plot
chart = alt.Chart(value_counts_df).mark_bar().encode(
x=alt.X('Value:N', axis=alt.Axis(title='Value')),
y=alt.Y('Count:Q', axis=alt.Axis(title='Count')),
tooltip=['Value', 'Count']
).properties(
title='Value Counts for Column Country'
)
# Save the chart
chart.save('value_counts_column_a_bar_chart.json')
But the second part was a little bit tricky since the chatbot didn’t have a read idea of how the structure of the file was formed, suggesting:
import plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets'][0]['data'][0]:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets'][0]['data']]
y = [d['Unique Value Count'] for d in chart_data['datasets'][0]['data']]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets'][0]['data']]
y = [d['Count'] for d in chart_data['datasets'][0]['data']]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
title='Value Counts for Column A',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
If you try to compile that it will return a KeyError:0 which is cause by the index of the chart_data[datasets][0] which is not correct.
Taking a look in the actual JSON structure you quickly find that the right key is data-85d48ef46f547bd16ab0f88b32c209fb, which bring us to the correct version:
import plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
y = [d['Unique Value Count'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
y = [d['Count'] for d in chart_data['datasets']['data-85d48ef46f547bd16ab0f88b32c209fb']]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
title='Value Counts for Country',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
Or even a more elegant one suggested by the LLM:
mport plotly.graph_objects as go
import json
# Load JSON data
with open('value_counts_column_a_bar_chart.json', 'r') as f:
chart_data = json.load(f)
# Find the correct data key within 'datasets'
data_key = list(chart_data['datasets'].keys())[0]
# Extract data for plotting correctly, handling both nominal and quantitative data
if 'Column Name' in chart_data['datasets'][data_key][0]:
# Nominal data (e.g., categories like 'A', 'B', 'C')
x = [d['Column Name'] for d in chart_data['datasets'][data_key][:10]]
y = [d['Unique Value Count'] for d in chart_data['datasets'][data_key][:10]]
else:
# Quantitative data (e.g., numeric values)
x = [d['Value'] for d in chart_data['datasets'][data_key][:10]]
y = [d['Count'] for d in chart_data['datasets'][data_key][:10]]
# Create Plotly bar chart
fig = go.Figure([go.Bar(x=x, y=y)])
# Customize layout (optional)
fig.update_layout(
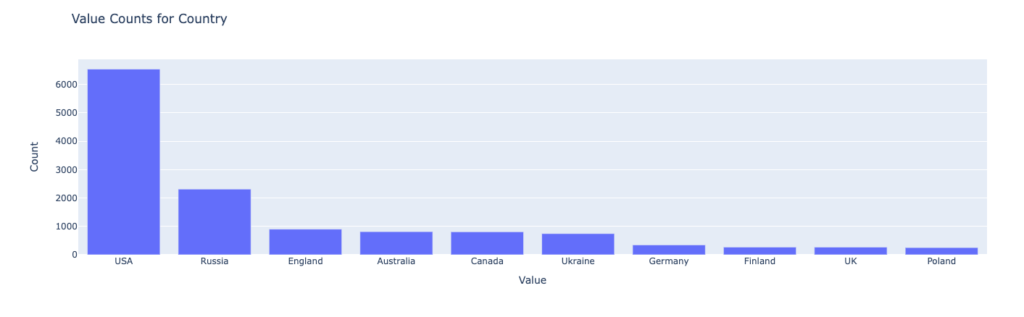
title='Value Counts for Country',
xaxis_title='Value',
yaxis_title='Count'
)
# Show the chart
fig.show()
Somewhere in the code is also a trim of the first 10 values in order to have similar outcomes. But the final plot looks like it should.
And that my friends is a small “pill” of working with Data Analysis, assisted by a LLM.
Some time ago, I tried to write some python code in order to grab each unique IP from my traffic logs and trying to trace it so that We can find similar nodes which were used for the jumps.
This is also a good exercise in order to improve the basic dataframe information and a good baseline for some explorations.
I will put here the code so that it is available for me as reference and also maybe for you if you want to take pieces of it.
I know that it is not optimised, but you can modify it or maybe use a chatbot to improve it.
import pymongo
import scapy.all as scapy
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
db = myclient["mydatabase"]
read_col = db["unique_ip"]
write_col = db["unique_ip_trace_tcp"]
lastid = 0
index_last_ip = write_col.find().sort([('_id', -1)]).limit(1)
for doc in index_last_ip:
doc['source_ip']
index_id = read_col.find({"payload":doc['source_ip']})
for elem in index_id:
lastid=elem['id']
print(lastid)
for i in range(lastid, read_col.count_documents({})):
mydoc = read_col.find({ "id": i })
for x in mydoc:
try:
for element in x['payload']:
response = {}
ans, unans = scapy.traceroute(element)
response['source_ip'] = element
payload = {}
for sdr,rcv in ans:
payload[str(sdr.ttl)]= rcv.src
response['payload'] = payload
write_col.insert_one(response)
except Exception as e:
print(e)
continue
Check it again and we also see that there are also two columns that are not really required: index and message which was returned by whois API. We drop those as well
And now we are finally ready to convert it and put it back to the database
# Convert DataFrame to a list of records
records = merged_df.to_records(index=False)
# Connect to MongoDB
client = MongoClient('localhost', 27017)
db = client['mydatabase']
base_merged_data = db['base_merged_data']
# Insert records into MongoDB collection
dicts = []
for record in records:
record_dict = {}
for field_name, value in zip(merged_df.columns, record):
record_dict[field_name] = value
dicts.append(record_dict)
base_merged_data.insert_many(dicts)
What I can tell you is that insert_many method is significantly faster than insert_one. At first I played with insert_one and it took 12 min to do the job, and with insert_many, that time was reduced to 3 min.
So today I played a little bit with the possibility of storing the unique IP addresses in a separate table.
Since I will use a subscription from ip-api.com, it seems that there is an option to query info by batch processing with a limit of 100 IP’s per payload.
So, at a first glance there are 227200 unique ip’s in my dataset. That will account for 2272 payloads to be queried.
The code more or less looks in the following way:
unique_ip = temp['SourceIP'].unique()
unique_list = [unique_ip[i:i + 100] for i in range(0, len(unique_ip), 100)]
data = []
for i in range(len(unique_list)):
temp_dict = {}
temp_dict['id'] = i+1
temp_dict['payload'] = unique_list[i].tolist()
data.append(temp_dict)
Once this is constructed you only need to parse the list element by element and insert it to MongoDB using this code:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["mydatabase"]
mycol = mydb["unique_ip"]
for i in range(len(data)):
mycol.insert_one(data[i])
Next step will involve taking the collection one by one and serve it to the API endpoint.
So, I managed to gather about 1 GB of records from the pfsense installation and grab them from the box (filter.log files that you can find under /var/log).
And I have a list of 16 logs that I need to concatenate.
I had a lot of trouble concatenating it since I tried multiple times to use writelines() method from the file object.
The code that worked for me:
outputcsv = open('//Users//tudorsorin//Downloads//var//log//firewallrepo//filter.csv','w')
f = open(f'//Users//tudorsorin//Downloads//var//log//firewallrepo//filter.concat', 'r')
lines = f.readlines()
for line in lines:
outputcsv.writelines(",".join(line.split(" ")[0:3])+","+line.split(" ")[-1])
f.close()
outputcsv.close()
The idea is that it’s already in CSV format and all you need to do is to modify the “header” that normally looks like Feb 20 07:58:18 soaretudorhome filterlog[41546]: to something like Feb,20, 07:58:18, and the rest remains the same.
Suprisingly, if you want to load it directly to a dataframe using pd.read_csv and you don’t force a header it works and I have all the data there with NaN in the fields that are not filled.
After this is done, we can filter only traffic that is done over ppoe0 which is the WAN interface, and you can easily do that using temp = df[df[‘pppoe0’] == ‘pppoe0’]
So far so good. I also took a look at a generic pppoe0 line and came to the conclusion that the colums that interest me are [0,1,2,21,22,23,24] which represent the date and source ip, destination ip and ports (source and destination). You can than filter the dataframe by temp = temp.iloc[:, [0,1,2,21, 22, 23, 24]]
So we finally we have a dateframe that we can work with. Now what remains is to change the table header and try to enhance it with extra info.
Today is a short example on cases that have longer columns with spaces.
For example. I have a dataframe that has the following columns:
I have read in some sources that you can use the construction wine_new.[column name].unique() to filter the values.
If you have a one word column, it will work, but if the column is listed as multiple words, you can not use a construct like wine_new.’Page ID’.unique() because it will give a syntax error.
Good, so you try to rename it. why Page ID and not pageid? Ok, that should be easy
But if you need to keep the column name, you can just as easily use wine_new[‘Page ID’].unique() (If you want to count the number of unique values you can also use wine_new[‘Page ID’].nunique())
There are multiple resources on this topic but the approach is not explained using both of the versions on the majority of them.