Morning,
Since i had a vacation and completely forgot all my passwords for Debian VM i fixed it using this article. Very useful!
https://pve.proxmox.com/wiki/Root_Password_Reset
Cheers!
Morning,
Since i had a vacation and completely forgot all my passwords for Debian VM i fixed it using this article. Very useful!
https://pve.proxmox.com/wiki/Root_Password_Reset
Cheers!
Hi,
Wanna share with you what managed to take me half a day to clarify. I just read in the following article https://docs.confluent.io/current/kafka/deployment.html#file-descriptors-and-mmap
and learned that in order to optimize kafka, you will need to also change the maximum number of open files. It is nice, but our clusters are deployed on Ubuntu and the images are pretty basic. Not really sure if this is valid for all of the distributions but at least for this one it’s absolutely needed.
Before trying to setup anything in
/etc/security/limits.conf
make sure that you have exported in
/etc/pam.d/common-session
line
session required pam_limits.so
It is needed in order for ssh, su processes to take the new limits for that user (in our case kafka).
Doing this will help you define new values on “limits” file. You are now free to setup nofile limit like this for example
* soft nofile 10000 * hard nofile 100000 kafka soft nofile 10000 kafka hard nofile 100000
After it is done, you can restart the cluster and check value by finding process with ps-ef | grep kafka and viewing limit file using cat /proc/[kafka-process]/limits.
I will come back later with also a puppet implementation for this.
Cheers!
Hi,
This is out of my expertise but i wanted to shared it anyways. One colleague wanted to help him with the creation of a pair key:value from one command that lists the processes, in python. With a little bit of testing i came to the following form:
import os
import subprocess
from subprocess import Popen, PIPE
username = subprocess.Popen(['/bin/ps','-eo','pid,uname'], stdout=PIPE, stderr=PIPE)
firstlist = username.stdout.read().split('\n')
dict = {}
for str in firstlist:
if (str != ''):
secondlist = str.split()
key = secondlist[0]
value = secondlist[1]
dict[key]=value
print(dict)
Now, i think there are better ways to write this but it works also in this way.
If you find better ways, please leave a message 🙂
Cheers
Hi,
One extra addition to my traefik balancing article from http://log-it.tech/2017/08/19/puppet-implementation-traefik-load-balancer-kafka-manager/ is that even so now we have the balancing capability we still need to restrict access to unsecured endpoint. I thought all the code to be deployable on all of the nodes. If this is taken in consideration, our issue with the firewall rules should be easily solved by using the puppetlabs module https://github.com/puppetlabs/puppetlabs-firewall and the code that i included looks like:
$hosts_count = $kafka_hosts.count
package {'iptables-persistent':
name => 'iptables-persistent',
ensure => installed,
}
resources { 'firewall':
purge => true,
}
$kafka_hosts.each | Integer $index,String $host | {
firewall {"10${index} adding tcp rule kafka manager node ${index}":
proto => 'tcp',
dport => 9000,
source => "${host}",
destination => "${fqdn}",
action => 'accept',
}
}
firewall {"10${hosts_count} droping rest of kafka manager calls":
proto => 'tcp',
dport => 9000,
destination => "${fqdn}",
action => 'drop',
}This should be add rules in order to allow traffic on port 9000 only between the kafka hosts that have kafka manager installed.
Cheers
Hi,
Today i am trying to show you what i have been playing with for the last day. There was a business case in which some colleagues from Analytics wanted to replicate all the data from other systems in their cluster.
We will start with this, two independent configured clusters with 3 servers each (on each server we have one zookeeper and one kafka node). On both the source and target i created a topic replicated three times with five partitions. You can find the description
/opt/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test-topic
Topic:test-topic PartitionCount:5 ReplicationFactor:3 Configs:
Topic: test-topic Partition: 0 Leader: 1002 Replicas: 1002,1003,1001 Isr: 1002,1003,1001
Topic: test-topic Partition: 1 Leader: 1003 Replicas: 1003,1001,1002 Isr: 1003,1001,1002
Topic: test-topic Partition: 2 Leader: 1001 Replicas: 1001,1002,1003 Isr: 1001,1002,1003
Topic: test-topic Partition: 3 Leader: 1002 Replicas: 1002,1001,1003 Isr: 1002,1001,1003
Topic: test-topic Partition: 4 Leader: 1003 Replicas: 1003,1002,1001 Isr: 1003,1002,1001
The command for creating this is actually pretty simple and it goes like this /opt/kafka/bin/kafka-topics.sh –zookeeper localhost:2181 –create –replication-factor 3 –partition 5 –topic test-topic
Once the topic are created on both kafka instances we will need to start Mirror Maker (HortonWorks recommends that the process should be created on the destination cluster). In order to do that, we will need to create two config files on the destination. You can call them producer.config and consumer.config.
For the consumer.config we have the following structure:
bootstrap.servers=source_node0:9092,source_node1:9092,source_node2:9092
exclude.internal.topics=true
group.id=test-consumer-group
client.id=mirror_maker_consumer
For the producer.config we have the following structure:
bootstrap.servers=destination_node0:9092,destination_node1:9092,destination_node2:9092
acks=1
batch.size=100
client.id=mirror_maker_producer
These are the principal requirements and also you will need to be sure that you have in you consumer.properties the following line group.id=test-consumer-group.
Ok, so far so good, now lets start Mirror Maker with and once started you can see it beside kafka and zookeeper using ps -ef | grep java
/opt/kafka/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config ../config/consumer.config --producer.config ../config/producer.config --whitelist test-topic &To check the offset, at new versions of kafka you can always use
/opt/kafka/bin# ./kafka-run-class.sh kafka.admin.ConsumerGroupCommand --group test-consumer-group --bootstrap-server localhost:9092 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
test-consumer-group test-topic 0 2003 2003 0 test-consumer-group-0_/[dest_ip]
test-consumer-group test-topic 1 2002 2002 0 test-consumer-group-0_/[dest_ip]
test-consumer-group test-topic 2 2003 2003 0 test-consumer-group-0_/[dest_ip]
test-consumer-group test-topic 3 2004 2004 0 test-consumer-group-0_/[dest_ip]
test-consumer-group test-topic 4 2002 2002 0 test-consumer-group-0_/[dest_ip]
I tested the concept by running a short loop in bash to create 10000 records and put them to a file for i in $( seq 1 10000); do echo $i; done >> test.txt and this can be very easily imported on our producer by running the command /opt/kafka/bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test-topic < test.txt
After this is finished, please feel free to take a look in the topic using /opt/kafka/bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test-topic –from-beginning and you should see a lot of lines 🙂
Thank you for your time and if there are any parts that i missed, please reply.
Cheers!
Hi,
As you probably know, Kafka is already publishing a lot of performance data on JMX to be collected.
In order to do this, you will need to install jconsole (for Windows it’s already embedded in the jdk installation, for Linux you can use this article to check it out https://www.garron.me/en/linux/find-which-package-library-belongs.html. After you have done that, you will have just to export the JMX_PORT variable to you env (for example export JMX_PORT=9999) before you start the Kafka node. When you will open JConsole you will probably see something like
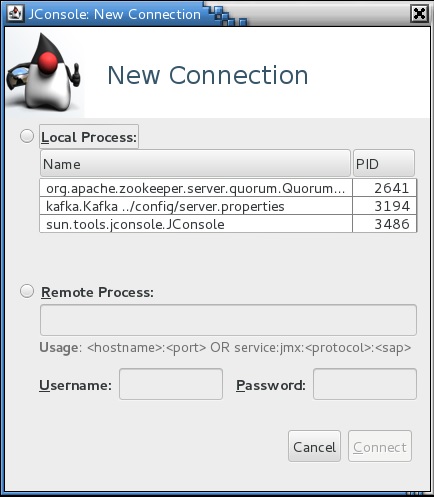
After you select the Kafka node, it will tell you that the connection is not secure, but it doesn’t matter for my point of view and after that you can have a overview of the process. The statistics are available MBens tab and extra info regarding the meaning you can find in the official doku and also in the DataDog article.
This is a single simple node configuration, if it is required i will post some complex configurations, but this is required in special cases, standard monitoring using DataDog/Prometheus or other solution needs to be implemented in case of a bigger infrastructure.
Cheers
Hi,
Just wanted to post this also, if it’s not that nice the config using a jumpserver, surely we can convert that to code (Puppet/Ansible), you can also use Vagrant. The main issue that i faced when i tried to create my setup is that for a reason (not really sure why, Vagrant on Windows runs very slow). However, i chose to give you one piece of Vagrantfile for a minimal setup on which you can grab the Rancher server framework and also the client containers.
Here is it:
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.define "master" do |master|
master.vm.box = "centos/7"
master.vm.hostname = 'master'
master.vm.network "public_network", bridge: "enp0s25"
end
config.vm.define "slave" do |slave|
slave.vm.box = "centos/7"
slave.vm.hostname = 'slave'
slave.vm.network "public_network", bridge: "enp0s25"
end
config.vm.define "swarmmaster" do |swarmmaster|
swarmmaster.vm.box = "centos/7"
swarmmaster.vm.hostname = 'swarmmaster'
swarmmaster.vm.network "public_network", bridge: "enp0s25"
end
config.vm.define "swarmslave" do |swarmclient|
swarmclient.vm.box = "centos/7"
swarmclient.vm.hostname = 'swarmclient'
swarmclient.vm.network "public_network", bridge: "enp0s25"
end
end
Do not worry about the naming of the machines, you can change them to whatever you like, the main catch is to bridge the public network in all of them in order to be able to communicate with each other and also have access to the docker hub. Beside that everything else that i posted regarding the registry to the Rancher framework is still valid.
Thank you for your time,
Cheers!
Hi,
I wanted to post this since it might be useful in some situations. On a Linux machine it seems that one way to check the memory usage by top processes is with ps aux –sort -rss (This means that it’s order by Resistent Set Size) Once executed it will return an output similar to this:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
sorin 3673 0.6 27.3 3626020 563964 pts/1 Sl+ 02:24 1:09 java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+Disa
sorin 1708 2.0 9.2 1835288 189692 ? Sl 02:11 3:56 /usr/bin/gnome-shell
sorin 1967 0.6 8.0 1642280 166160 ? Sl 02:12 1:11 firefox-esr
sorin 3413 0.1 3.7 2000252 77016 pts/0 Sl+ 02:21 0:19 java -Xmx512M -Xms512M -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+
root 576 0.5 2.6 263688 54172 tty7 Ssl+ 02:11 1:07 /usr/bin/Xorg :0 -novtswitch -background none -noreset -verbose 3 -auth /var/run/gdm3/auth-for-Debian-gdm-Bu1jB
sorin 1813 0.0 2.2 1175504 47196 ? Sl 02:11 0:00 /usr/lib/evolution/evolution-calendar-factory
root 486 0.1 1.2 377568 26584 ? Ssl 02:11 0:21 /usr/bin/dockerd -H fd://If you want to get more detail of a PID status you can go to /proc/[pid]/status and you can find a lot of other informations. For example the top process on my Linux machine has the following header:
sorin@debian:/proc/3673$ cat status
Name: java
State: S (sleeping)
Tgid: 3673
Ngid: 0
Pid: 3673
PPid: 3660
TracerPid: 0
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
FDSize: 256
Groups: 24 25 29 30 44 46 108 111 116 1000
VmPeak: 3626024 kB
VmSize: 3626020 kBAs you can see, the RSS is the same as VmSize.
Cheers!
Hi,
After we were able to login via ssh on our machines, it’s time to put them to use by subscribing them to a orchestrating framework. One free and pretty powerful framework of such kind is given by the same company. In order to use it you will need to have Docker installed, more info on this topic following the link
https://docs.rancher.com/rancher/v1.5/en/installing-rancher/installing-server/
Until now i haven’t tried the option for a HA configuration, i will do that in the near future and post the findings but for now it should be enough if we deploy a standard container for the management.
Using the command from the documentation i have managed to grab the image and start the following container:
417930c9f375 rancher/server "/usr/bin/entry /u..." 2 weeks ago Up 6 minutes 3306/tcp, 0.0.0.0:8080->8080/tcp eloquent_goodall
We have also the possibility to check the image using the docker images command and we will have the following result:
rancher/server latest 2751db6ea7ec 4 weeks ago 935 MB
Once the container is started, you can access the UI by going to the address http://127.0.0.1:8080 (please keep in mind that you have binded the ports to be forwarded and accessible from any IP range, that is what 0.0.0.0:8080->8080/tcp should mean, if you want to be accessible for a specific range or IP please change this on docker run command.
Ok, once the administration console has been loaded you can go to Infrastructure -> Hosts -> Add Host. Please do not use the default site address, it is relevant only for the local container, instead it can be replaced by http://[jumpserver ip address]:8080. This will be used in order to obtain the registration string for the agents. When pressing OK, you will be redirected to a window with the necessary steps to be done for registration, please keep it open.
After connecting via ssh to the Rancher machine, please make sure that you have access to the Docker hub repo. You can easily do that by running docker search rancher. If there is a timeout error, please take a look on configuring proxy for docker, in our case on private machines it can be done using the following lines in cloud-config.yml located under /var/lib/rancher/conf
rancher:
network:
http_proxy: http://[user]:[password]@[proxyip]:[proxyport]
https_proxy: http://[user]:[password]@[proxyip]:[proxyport]These lines being added you will need to reload the docker daemon by using the command system-docker restart docker and it should work.
Now go to the UI page and copy the string at the last step in our Rancher server window, it will start downloading the necessary containers in order to link with the framework.
This being done some images will be downloaded and started to the machine and started:
[rancher@rancher conf]$ docker images | grep rancher
rancher/scheduler v0.7.5 e7ff16ba4444 2 weeks ago 241.9 MB
rancher/network-manager v0.5.3 0f224908d730 2 weeks ago 241.6 MB
rancher/metadata v0.8.11 19b37bb3e242 5 weeks ago 251.5 MB
rancher/agent v1.2.1 9cecf992679f 5 weeks ago 233.7 MB
rancher/scheduler v0.7.4 7a32d7571cad 5 weeks ago 241.9 MB
rancher/net v0.9.4 5ac4ae5d7fa4 5 weeks ago 264.3 MB
rancher/network-manager v0.4.8 45bdcd2b1944 6 weeks ago 241.6 MB
rancher/dns v0.14.1 4e37fc4150c2 6 weeks ago 239.8 MB
rancher/healthcheck v0.2.3 491349141109 10 weeks ago 383.3 MB
rancher/net holder bb516596ce5a 3 months ago 261.7 MB[rancher@rancher conf]$ docker ps -a | grep rancher
a3fde18ebdbd rancher/scheduler:v0.7.5 "/.r/r /rancher-entry" 3 days ago Exited (0) 3 days ago r-scheduler-scheduler-1-37fd65ec
35c7bbc1cb42 rancher/network-manager:v0.5.3 "/rancher-entrypoint." 3 days ago Up 30 minutes r-network-services-network-manager-1-57e1bbbd
3a048010be3d rancher/scheduler:v0.7.4 "/.r/r /rancher-entry" 2 weeks ago Exited (0) 3 days ago r-scheduler-scheduler-1-de6ec66f
fad7d11141aa rancher/net:v0.9.4 "/rancher-entrypoint." 2 weeks ago Up 29 minutes r-ipsec-ipsec-router-1-af053a8c
b7ce7b4f8520 rancher/dns:v0.14.1 "/rancher-entrypoint." 2 weeks ago Up 30 minutes r-network-services-metadata-dns-1-438fbeaa
30e5cab4b4c6 rancher/metadata:v0.8.11 "/rancher-entrypoint." 2 weeks ago Up 30 minutes r-network-services-metadata-1-827c71e3
382ebf55c3c1 rancher/net:holder "/.r/r /rancher-entry" 2 weeks ago Up 30 minutes r-ipsec-ipsec-1-55aeea30
0223f1ffe986 rancher/healthcheck:v0.2.3 "/.r/r /rancher-entry" 2 weeks ago Up 30 minutes r-healthcheck-healthcheck-1-f00a6858
03652d781c9a rancher/net:v0.9.4 "/rancher-entrypoint." 2 weeks ago Up 30 minutes r-ipsec-ipsec-cni-driver-1-797e0060
1b6d1664c801 rancher/agent:v1.2.1 "/run.sh run" 2 weeks ago Up 31 minutes rancher-agent
c8b8e4ddf91c rancher/agent:v1.2.1 "/run.sh http://10.0." 2 weeks ago Exited (0) 2 weeks ago furious_bohrAnd also the server will appear in the UI. In next posts we will try to deploy some services from the catalog.
Cheers