There was a issue on options that aggregate any other ones, like -A for my previous post
In my view the easiest way to solve it is by storing the options in a tuple.
Here is the snippet
run_options = []
try:
opts, args = getopt.gnu_getopt(sys.argv[1:-1], 'AbeEnstTv', ['show-all', 'number-nonblank', 'show-ends', 'number', 'show-blank', 'squeeze-blank' 'show-tabs', 'show-nonprinting', 'help', 'version'])
except getopt.GetoptError:
print("Something went wrong")
sys.exit(2)
for opt, arg in opts:
if opt in ('-A','--show-all'):
run_options.append('E')
run_options.append('T')
elif opt in ('-b', '--number-nonblank'):
run_options.append('b')
elif opt in ('-n', '--number'):
run_options.append('n')
elif opt in ('-E', '--show-ends'):
run_options.append('E')
elif opt in ('-s', '--squeeze-blank'):
run_options.append('s')
elif opt in ('-T', '--show-tabs'):
run_options.append('T')
final_run_options = tuple(run_options)
for element in final_run_options:
if element == 'b':
content_list = number_nonempty_lines(content_list)
elif element == 'n':
content_list = number_all_lines(content_list)
elif element == 'E':
content_list = display_endline(content_list)
elif element == 's':
content_list = squeeze_blanks(content_list)
elif element == 'T':
content_list = show_tabs(content_list)
So basically, you store the actual cases in a list which you convert to a tuple to eliminate duplicates. Once you have the final case, you parse it and change the actual content option by option.
I didn’t have the time to test it but there is no big reason why it should’t work.
Since I am striving to find useful content to post more often, I took homework for a ‘cat’ written in Python.
It’s not elegant, and it’s not the best version but it works.
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 25 10:28:39 2019
@author: Sorin
"""
import sys,getopt,os
if os.path.isabs(sys.argv[-1:][0]):
FILENAME= sys.argv[-1:][0]
else:
FILENAME = os.getcwd() + "\\" + sys.argv[-1:][0]
def read_content(filename):
try:
f = open(filename, "r+")
content = f.read()
f.close()
except IOError as e:
print("File could not be opened:", e)
sys.exit(3)
return content
def transform_content():
content = read_content(FILENAME)
content_list = content.split('\n')
return content_list
def number_nonempty_lines(content_list):
i = 0
for line in content_list:
if line != '':
content_list[i] = str(i) + " " + line
i = i + 1
return content_list
def squeeze_blanks(content_list):
i = 0
duplicate_index = []
for line in content_list:
if (line == "" or line == "$") or (str.isdigit(line.split(' ')[0]) and (line.split(' ')[-1] == "" or line.split(' ')[-1] == "$")):
duplicate_index.append(i+1)
i = i + 1
delete_index = []
for j in range(len(duplicate_index) - 1):
if duplicate_index[j] + 1 == duplicate_index[j+1]:
delete_index.append(duplicate_index[j])
for element in delete_index:
content_list.pop(element)
return content_list
def number_all_lines(content_list):
i = 0
for line in content_list:
content_list[i] = str(i) + " " + line
i = i + 1
return content_list
def display_endline(content_list):
return [line + "$" for line in content_list]
def show_tabs(content_list):
print(content_list)
content_list = [ line.replace('\t','^I') for line in content_list]
return content_list
content_list =transform_content()
try:
opts, args = getopt.gnu_getopt(sys.argv[1:-1], 'AbeEnstTv', ['show-all', 'number-nonblank', 'show-ends', 'number', 'show-blank', 'squeeze-blank' 'show-tabs', 'show-nonprinting', 'help', 'version'])
except getopt.GetoptError:
print("Something went wrong")
sys.exit(2)
for opt, arg in opts:
if opt in ('-A','--show-all'):
content_list = display_endline(content_list)
content_list = show_tabs(content_list)
elif opt in ('-b', '--number-nonblank'):
content_list = number_nonempty_lines(content_list)
elif opt in ('-n', '--number'):
content_list = number_all_lines(content_list)
elif opt in ('-E', '--show-ends'):
content_list = display_endline(content_list)
elif opt in ('-s', '--squeeze-blank'):
content_list = squeeze_blanks(content_list)
elif opt in ('-T', '--show-tabs'):
content_list = show_tabs(content_list)
print('\n'.join(content_list))
Further improvements will be also posted. I must confess that there are still a couple of things to be fixed, like not running the same options twice, and the issue of putting it to work on very large files, but it will do in this form for now.
There are a lot of pages on how to query ELK stack from Python client library, however, it’s still hard to grab a useful pattern.
What I wanted is to translate some simple query in Kibana like redis.info.replication.role:master AND beat.hostname:*test AND tags:test into a useful Query DSL JSON.
It’s worth mentioning that the Python library uses this DSL. Once you have this info, things get much simpler.
Well, if you search hard enough, you will find a solution, and it should look like.
Here are some first steps that I want to share with you from my experience with regressions.
I am new and I took it to step by step, so don’t expect anything new or either very complex.
First thing, first, we started working on some prediction “algorithms” that should work with data available in the operations domain.
We needed to have them stored in a centralized location, and it happens that they are sent to ELK. So, the first step is to query then from that location.
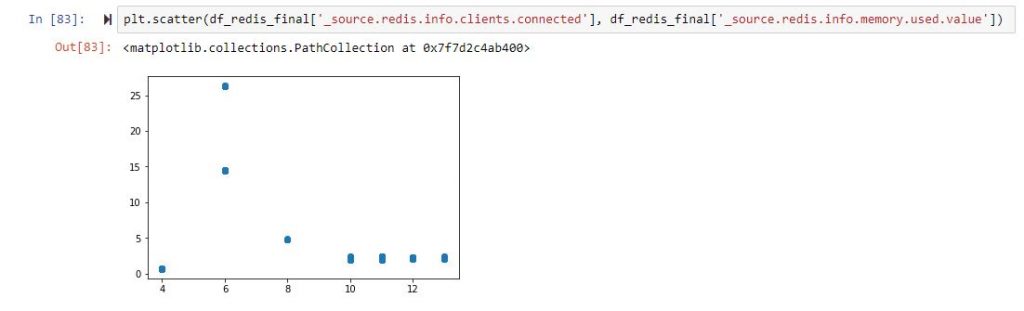
To do that, there is a python client library with a lot of options that I am still beginning to explore. Cutting to the point, to have a regression you need a correlation parameter between the dependent and independent variable, so we thought at first about links between the number of connection and memory usage of a specific service (for example Redis). And this is available with some simple lines of code in Jupyter:
For a little bit of explaining, the used memory needs to be divided to ten to the sixth power in order to transform from bytes to MBytes, and also I wanted to exclude values of memory over 300MB. All good, unfortunately, if you plot the correlation “matrix” between these params, this happens:
As far as we all should know, a correlation parameter should be as close as possible to 1 or -1, but it’s just not the case.
And if you want to start plotting, it will look something like:
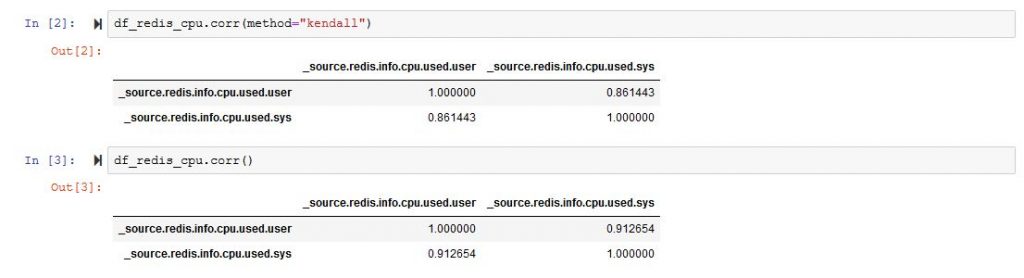
So, back to the drawing board, and we now know that we have no clue which columns are correlated. Let us not filter the columns and just remove those that are non-numeric or completely filled with zeros.
I used this to manipulate the data as simple as possible:
And it will bring you a very large matrix with a lot of rows and columns. From that matrix, you can choose two data types that are more strongly correlated. In my example [‘_source.redis.info.cpu.used.user’,’_source.redis.info.cpu.used.sys’]
If we plot the correlation matrix just for those two colums we are much better than at the start.
So we are better than before, and we can now start thinking of plotting a regression, and here is the code for that.
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
import pandas as pd
x = df_redis_cpu['_source.redis.info.cpu.used.user']
y = df_redis_cpu['_source.redis.info.cpu.used.sys']
x = x.values.reshape(-1, 1)
y = y.values.reshape(-1, 1)
x_train = x[:-250]
x_test = x[-250:]
y_train = y[:-250]
y_test = y[-250:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(x_train, y_train)
# Plot outputs
plt.plot(x_test, regr.predict(x_test), color='red',linewidth=3)
plt.scatter(x_test, y_test, color='black')
plt.title('Test Data')
plt.xlabel('User')
plt.ylabel('Sys')
plt.xticks(())
plt.yticks(())
plt.show()
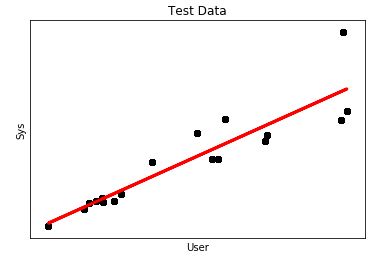
Our DataFrame contains 1000 records from which I used 750 to “train” and another 250 to “test”. The output looked this way
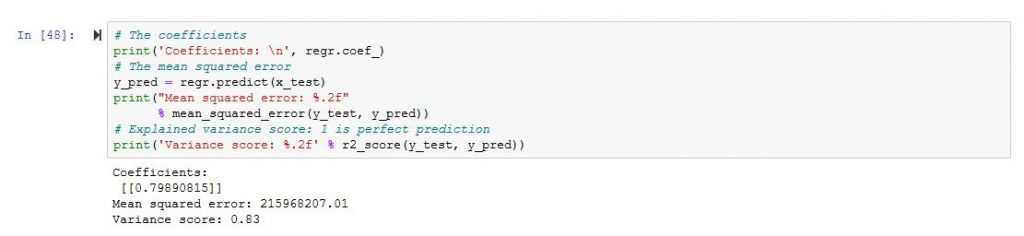
It looks more like a regression, however, what concerns me is the mean square error which is a little bit high.
So we will need to works further on the DataFrame 🙂
In order for the linear model to be applied with scikit, the input and output data are transformed into single dimension vectors. If you want to switch back and for example to create a DataFrame from the output of the regression and the actual samples from ELK, it can be done this way:
It’s not elegant by any means, but it works. As an advise, please don’t over complicate thinks more than they need.
In the last example i figured i wanted to create a list of GroupInfo objects for each line that was returned from consumer group script. Bad idea as you shall see below
So, in addition to what i wrote in the last article, now it’s not just printing the dictionary but order it, by partition.
def constructgroupdict():
groupagregate = {}
group_list = getgroups()
for group in group_list:
groupagregate[group] = getgroupinfo(group)
for v in groupagregate.values():
v.sort(key = lambda re: int(re.partition))
return groupagregate
def printgroupdict():
groupdict = constructgroupdict()
infile = open('/etc/datadog-agent/conf.d/kafka_consumer.d/kafka_consumer.yaml.template','a')
for k,v in groupdict.items():
infile.write(' '+k+':\n')
topics = []
testdict = {}
for re in v:
if re.topic not in topics:
topics.append(re.topic)
for x in topics:
partitions = []
for re in v:
if (re.topic == x):
partitions.append(re.partition)
testdict[x] = partitions
for gr,partlst in testdict.items():
infile.write(' '+gr+': ['+', '.join(partlst)+']\n')
infile.close()
os.rename('/etc/datadog-agent/conf.d/kafka_consumer.d/kafka_consumer.yaml.template','/etc/datadog-agent/conf.d/kafka_consumer.d/kafka_consumer.yaml')
printgroupdict()
And after that, it’s quite hard to get only the unique value for the topic name.
The logic i chose to grab all the data per consumer group is related to the fact that querying the cluster takes a very long time, so if i wanted to grab another set of data filtered by topic, i would have been very time costly.
In the way that is written now, there are a lot of for loop, that should become challenging in care there are too many records to process. Fortunately, this should not be the case for consumer groups in a normal case.
The easiest way to integrate the info in kafka_consumer.yaml, in our case is to create a template called kafka_consumer.yaml.template
init_config:
# Customize the ZooKeeper connection timeout here
# zk_timeout: 5
# Customize the Kafka connection timeout here
# kafka_timeout: 5
# Customize max number of retries per failed query to Kafka
# kafka_retries: 3
# Customize the number of seconds that must elapse between running this check.
# When checking Kafka offsets stored in Zookeeper, a single run of this check
# must stat zookeeper more than the number of consumers * topic_partitions
# that you're monitoring. If that number is greater than 100, it's recommended
# to increase this value to avoid hitting zookeeper too hard.
# https://docs.datadoghq.com/agent/faq/how-do-i-change-the-frequency-of-an-agent-check/
# min_collection_interval: 600
#
# Please note that to avoid blindly collecting offsets and lag for an
# unbounded number of partitions (as could be the case after introducing
# the self discovery of consumer groups, topics and partitions) the check
# will collect at metrics for at most 200 partitions.
instances:
# In a production environment, it's often useful to specify multiple
# Kafka / Zookeper nodes for a single check instance. This way you
# only generate a single check process, but if one host goes down,
# KafkaClient / KazooClient will try contacting the next host.
# Details: https://github.com/DataDog/dd-agent/issues/2943
#
# If you wish to only collect consumer offsets from kafka, because
# you're using the new style consumers, you can comment out all
# zk_* configuration elements below.
# Please note that unlisted consumer groups are not supported at
# the moment when zookeeper consumer offset collection is disabled.
- kafka_connect_str:
- localhost:9092
zk_connect_str:
- localhost:2181
# zk_iteration_ival: 1 # how many seconds between ZK consumer offset
# collections. If kafka consumer offsets disabled
# this has no effect.
# zk_prefix: /0.8
# SSL Configuration
# ssl_cafile: /path/to/pem/file
# security_protocol: PLAINTEXT
# ssl_check_hostname: True
# ssl_certfile: /path/to/pem/file
# ssl_keyfile: /path/to/key/file
# ssl_password: password1
# kafka_consumer_offsets: false
consumer_groups:
It’s true that i keep only one string for connectivity on Kafka and Zookeeper, and that things are a little bit more complicated once SSL is configured (but this is not our case, yet).
I’ve been playing with kafka-python module to grab the info i need in order to reconfigure Datadog integration.
Unfortunately, there is a catch also on this method. And i will show you below.
Here is a little bit of not so elegant code.
from kafka import BrokerConnection
from kafka.protocol.admin import *
import socket
fqdn = socket.getfqdn()
bc = BrokerConnection(fqdn,9092,socket.AF_INET)
try:
bc.connect_blocking()
except Exception as e:
print(e)
if bc.connected():
print("Connection to", fqdn, " established")
def getgroup():
list_groups_request = ListGroupsRequest_v1()
future0 = bc.send(list_groups_request)
while not future0.is_done:
for resp, f in bc.recv():
f.success(resp)
group_ids = ()
for group in future0.value.groups:
group_ids += (group[0],)
print(group_ids)
description = DescribeGroupsRequest_v1(group_ids)
future1 = bc.send(description)
while not future1.is_done:
for resp, f in bc.recv():
f.success(resp)
for groupid in future1.value.groups:
print('For group ',groupid[1],':\n')
for meta in groupid[5]:
print(meta[0],meta[2],sep="\n")
print(meta[3])
if future1.is_done:
print("Group query is done")
getgroup()
As you will see, print(meta[3]) will return a very ugly binary data with topic names in it, that is not converted if you try with meta[3].decode(‘utf-8’)